[Node.js进阶] 子进程与Cluster
node.js的官方文档非常详细, 这里概括性的整理一些常用的和重要的地方, 完整的方法、参数等还是要参考官方文档. 另外, 本文还记录一个基于cluster模块封装的生产环境上必备的守护进程模块pm2的使用
Node.js创建子进程及进程间通信
核心函数spawn
child_process模块可以赋予node.js创建子进程的能力, 其中包括以下几个函数:
- exec(command[, options][, callback])
- execFile(file[, args][, options][, callback])
- fork(modulePath[, args][, options])
- spawn(command[, args][, options])
- execSync / execFileSync / spawnSync 等用于创建阻塞的同步进程
其中spawn函数的作用是: 启动一个进程来执行命令, 其他几个方法如fork, exec等都是对spawn的封装, 更加方便使用.
比如这个例子使用spawn执行了一个bat批处理文件, 并且演示了常用的一些进程间通信的方式
1 | const { spawn } = require('child_process'); |
上面这段代码, 在当前目录作为工作目录的情况下, 创建了一个执行spawn.bat的进程, 同时传入了一个叫做”arg2”的环境变量, 再将stdin重定向为父进程的输入, stdout和stderr输出流使用管道”输送”到父进程中, 并监听子进程标准输出的”data”事件, 以及进程的退出事件. 信息量不少, spawn常见的用法都囊括其中了. 其中stdio的配置很灵活, inherit表示重定向到父端, pipe是默认值, ignore表示忽略子进程标准输入输出对应的文件描述符(FD), stdio配置的数组的前三个表示stdin, stdout, stderr, inherit相当于重定向到ChildProcess对象的stdin/stdout/stderr, 数组后面还可以添加自定义的字符串用作进程间通信的命名管道, 其值为’pipe’, ‘ipc’, ‘ignore’, null, Stream之一.
下面是spawn.bat的脚本代码.
1 | @echo off |
exec/execFile/fork
这三兄弟都是对spawn的封装, 官方文档是这样描述的:
- exec: 衍生一个 shell,然后在 shell 中执行 command,且缓冲任何产生的输出
- execFile: 不衍生 shell, 而是指定的可执行的 file 被直接衍生为一个新进程
- fork: 专门用于衍生新的 Node.js 进程, 返回一个ChildProcess对象
由此可以看出它们的区别和联系, 如下
- exec相比spawn, 会缓冲输出直到子进程结束, 不会持续产生”data”事件
- execFile与exec很像, 但由于它不启动shell执行命令, 而是直接运行一个可执行文件, 从而效率更高
- fork与前两者关系不大, 是一种用于衍生Node进程的特殊spawn, 并且还封装了一个IPC管道, 用于进程间通信
奉上一些示例代码:
1 | const { exec, execFile, spawn, fork } = require('child_process'); |
其中fork的示例, 在child.js中通过process监听message事件与父进程通信, 以下是child.js的代码
1 | process.on('message', (m) => { |
进程间通信
抛开Node.js, 进程间通信的方式有很多, 管道、命名管道、消息队列、共享存储、信号量、套接字、信号等等. 在child_process模块中使用的主要是管道和命名管道的方式
管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用.进程的亲缘关系一般指的是父子关系.管道一般用于两个不同进程之间的通信.当一个进程创建了一个管道,并调用fork创建自己的一个子进程后,父进程关闭读管道端,子进程关闭写管道端,这样提供了两个进程之间数据流动的一种方式. 命名管道也是一种有名字的先进先出队列(FIFO),但是它允许无亲缘关系进程间的通信.
同一台设备上的进程间通信, 不管是管道还是队列, 亦或是信号量, Unix Domain Socket, 本质上都是在访问共享的一块内存区域. 进程间通信是一个很复杂的话题, 每种方式有它的优势和缺点, 此处不再展开. 在Node.js中使用spawn()传入配置 stdio: ‘ipc’ 或者用fork()自带的以默认文件描述符NODE_CHANNEL_FD通信都能达到目标.
Cluster模块详解
cluster模块就是child_process和net模块的组合应用. cluster启动时, 会在内部启动一个TCP服务器, 在cluster.fork()子进程时, 将这个TCP服务器端的socket对应的文件描述符发送给工作进程, 如果工作进程中存在listen()侦听网络端口的调用, 它将拿到该文件描述符, 通过SO_REUSEADDR端口重用, 从而实现多个子进程共享端口
这段话摘自《深入浅出Node.js》,说明了cluster端口重用的工作原理, 用代码来说明大概是这样的:
1 | var child1 = require('child_process').fork('child.js'); |
“集群”的创建和事件监听
这里的集群打了引号, 是因为cluster模块并不能创建大规模集群, 只是通过多进程来提高对多核设备的硬件利用率, 以此进一步提高应用性能的一种方案. 真正的高可用大规模集群搭建和cluster模块并没有多大关系, 后面会写一些使用kubernetes和容器技术来搭建真正集群的文章. Node.js中cluster的创建和事件监听是这样的:
1 | const cluster = require('cluster'); |
worker进程的调度
上面的示例中, cluster有一个schedulingPolicy的配置, Round-Robin和抢占式, Windows默认的是SCHED_NONE, 也就是让操作系统自己调度; nix默认的是*SCHED_RR, 即轮叫调度. 官方文档对于调度的说明是这样的:
除Windows外的所有操作系统中,SCHED_RR都是默认设置。只要libuv可以有效地分发IOCP handle,而不会导致严重的性能冲击的话,Windows系统也会更改为SCHED_RR。cluster.schedulingPolicy 可以通过设置NODE_CLUSTER_SCHED_POLICY环境变量来实现。这个环境变量的有效值包括”rr” 和 “none”
这里提到了Node在Windows下采用IOCP实现异步, 顺便解释一下IOCP
IOCP是Windows有一种独有的内核异步IO方案。IOCP的思路是真正的异步I/O方案,调用异步方法,然后等待I/O完成通知。IOCP内部依旧是通过线程实现,不同在于这些线程由系统内核接手管理。
libuv屏蔽了不同平台下异步调用的实现, *nix中没有IOCP, libuv是直接对多线程进行封装实现异步的(并非epoll), 操作系统的差异体现在cluster模块上就是调度的不确定性. 这里有一篇写的不错的文章, 结论是由于Node.js的IPC管道性能和负载均衡不太靠谱, 提到了使用多个独立的Node进程 + nginx upstream负载比直接使用cluster更优, 后面有空来做一个验证.
PM2模块实践
PM2 is a General Purpose Process Manager and a Production Runtime for Node.js apps with a built-in Load Balancer.
翻译一下就是: “PM2是一个内置负载均衡的Node.js中通用进程管理器以及生产环境运行时”
PM2模块用起来很简单, 两行就可以在不改变任何代码的情况下, 建立一个Node集群
1 | npm install pm2 -g |
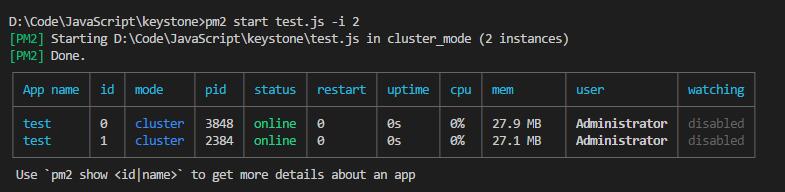
其他常用的命令如stop/restart/kill/logs/monit等也非常简洁易用, 并且还能集成keymetrics打造非常酷炫的监控, 集成过程只要一行命令
1 | # 注册后的key |
效果如下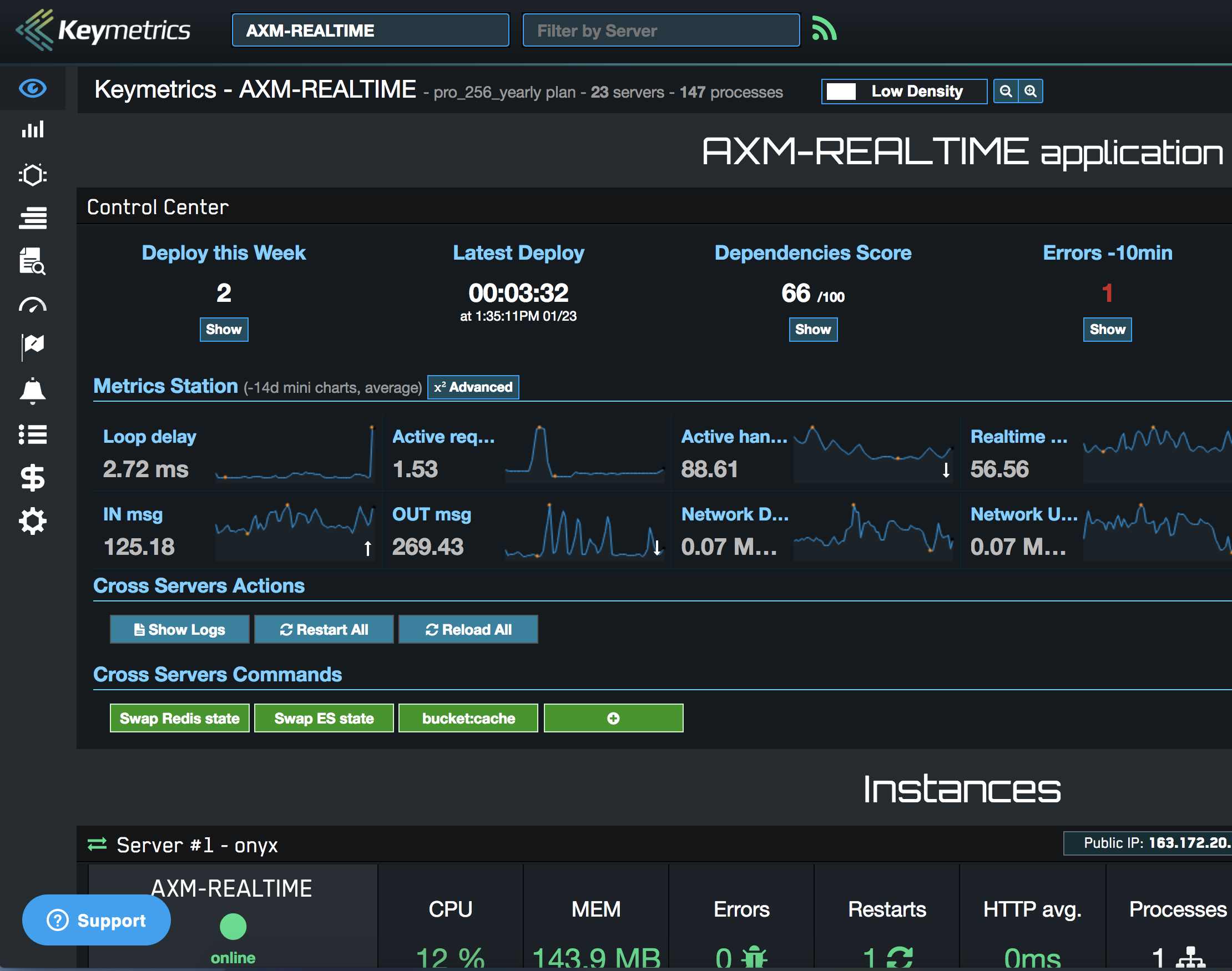
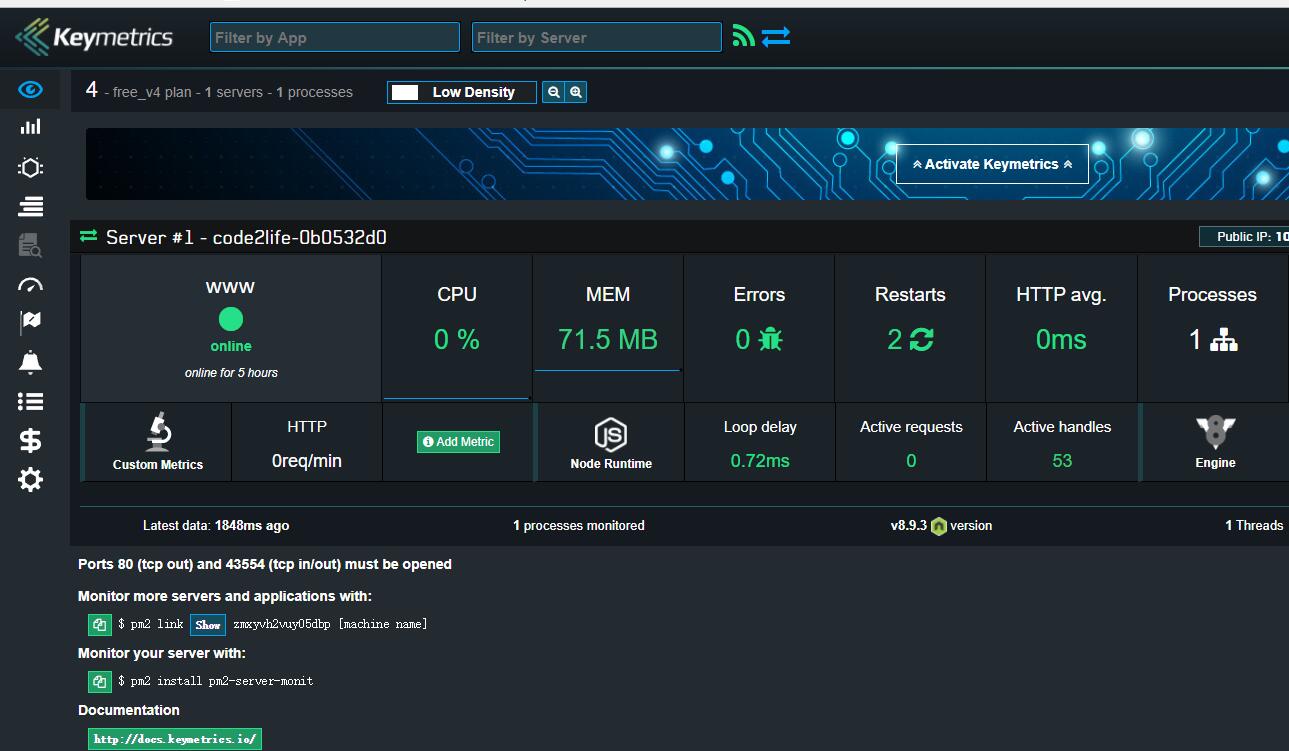
监控的UI确实不错, 而且pm2不仅适用于Nodejs, 其他服务和应用也可以. 但是说了这些优点, pm2也有一些缺点, 比如无法管理多台服务器上的Node进程, 共享Socket带来的性能损失等. 我个人感觉pm2适用于小型应用的生产环境, 分布式的中大型应用选用成熟的组件更加靠谱, 比如上面提到的nginx或haproxy做负载, 应用和服务器监控使用grafana/zabbix等等, 或者使用alinode的一站式服务. 毕竟pm2还是基于cluster模块的二次封装, cluster做不好的, pm2有同样的局限性.