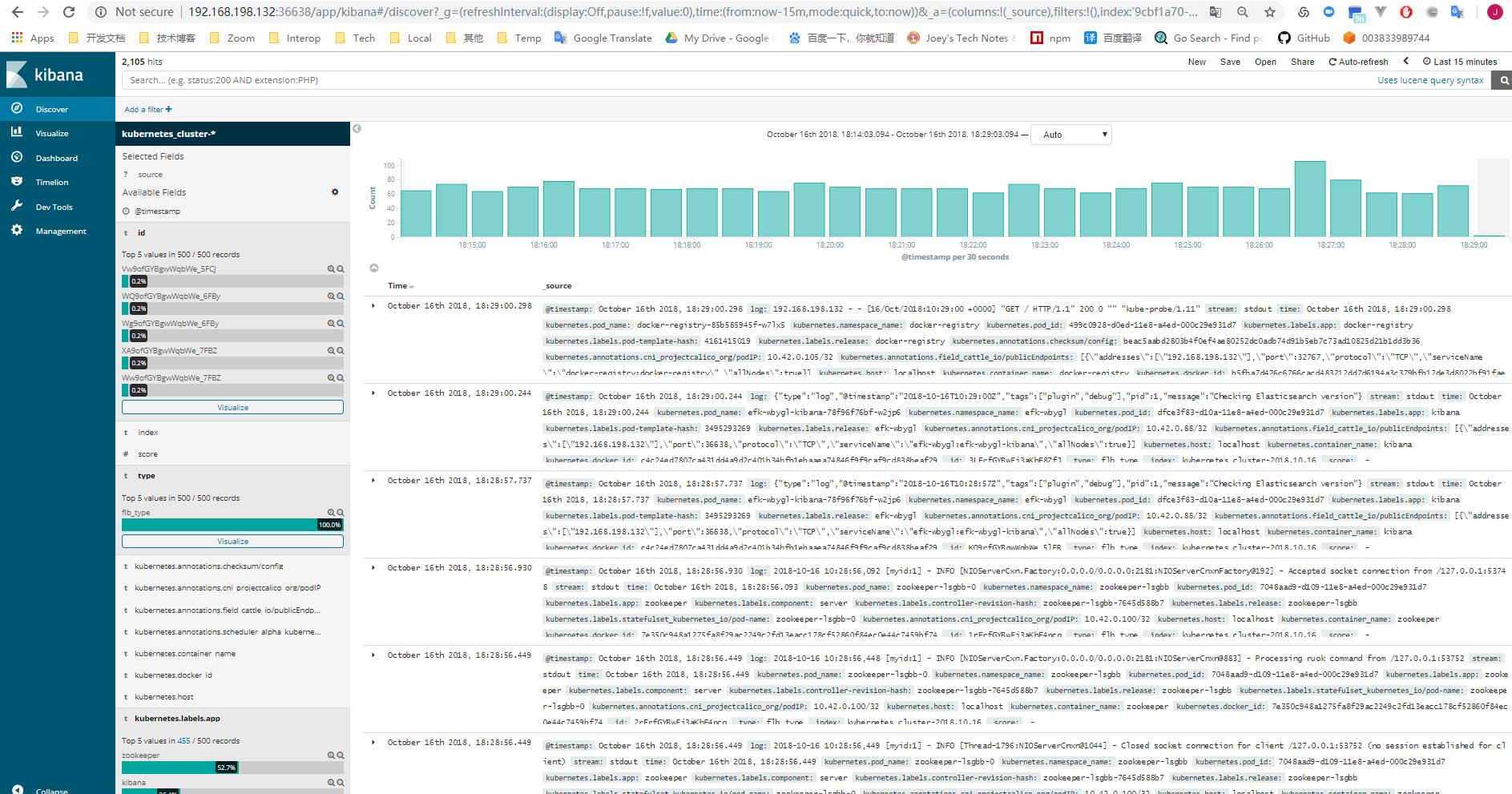
[分布式专题] DevOps平台Rancher试用笔记
2020年更新,Rancher版本迭代比较快,删改了部分内容,移步我的知乎专栏文章:https://zhuanlan.zhihu.com/p/184654439
Rancher的背景和定位
Kubernetes从Borg的原型发展到如今成为”云原生操作系统”这么一个重要的开源项目, 不仅是本身对计算资源抽象带来的分布式计算的变革, 也离不开周边繁荣的生态系统, Rancher就是其中之一. Kubenertes直接解决了集群的容器编排, 统一了资源管理接口, 但没有提供整个运维链的闭环解决方案. Rancher的目的就是提供一整套大而全的解决方案. 不仅囊括的集群资源的管理, 还集成日志/监控/预警, 甚至2.x版本加入的持续交付能力.
这一套解决方案并不需要对K8S本身有非常深刻的了解, 极大的降低了学习成本. 另外Rancher公司一边提供开源的软件, 一边提供付费的服务, 如果对Kubernetes本身理解到位的话, 出现问题是不需要付费服务就可以解决的.
Rancher有哪些好处
笔者一开始了解Kubernetes时, 看了一堆概念和一堆组件, 但还没有把集群搭出来, 因为Kubernetes这套子组件太多了, 手动部署的成本很高. 因此出现了很多自动化部署Kubernetes集群的软件, 比如这些:
- minukube 单机玩玩, 不能用于生产环境
- kubeadm 据说比较复杂, 相对比较黑盒
- kubeasz 完全ansible-playbook部署, 完全白盒, 不用去墙外下载任何东西, 非常适合国情
- kismatic Go封装了ansible以及ssh的细节, 相对白盒, 个性化配置和版本跟进有些不足
- rancher/rke 开箱即用, 兼容云服务商以及独立维护的机器, 比较灵活.
- AKS / EKS / GKE 云服务商直接提供高可用的Control Plane (api-server + controller-manager + scheduler + etcd + HA …)
能用在生成环境的大概是后面的4种, kubeasz和kismatic适合更专业的有ansible背景的运维人员, Rancher和EKS等方案适合小白以及对ansible和kubernetes不够了解的开发和运维人员. 笔者抱着试一试的态度用了两天的Rancher, 发现它的优势不仅是能方便的创建一个集群, 更在于它降低了开发测试运维人员的”心智成本”来管理集群. 对比几种管理集群的方案, rancher有天然的优势.
- kubectl + helm 命令行, 万金油, 灵活高效, 缺点是有一定学习成本且不够直观, 适合专业的运维人员
- 直接调用 kubernetes API, 可用于二次开发, 学习开发成本很高
- kubernetes-dashboard, 仅支持cluster资源对象管理, 不够全面
- rancher 多集群用户/资源管理-服务编排-监控预警-持续交付平台
它的功能特性优点确实如官网的宣传一样, 名副其实了. 这是几条体验比较深的:
- Install and manage Kubernetes clusters on any infrastructure.
- Provision and manage GKE, AKS, and EKS clusters
- Centralized Security Policy Management
- Monitoring, capacity management and alerts
- Complete UI for Managing Workloads
- User Projects Spanning Multiple Namespaces
- Integrated CI/CD Pipelines
Rancher平台试用经历
首先一行命令把Rancher跑起来
1 | sudo docker run -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/rancher |
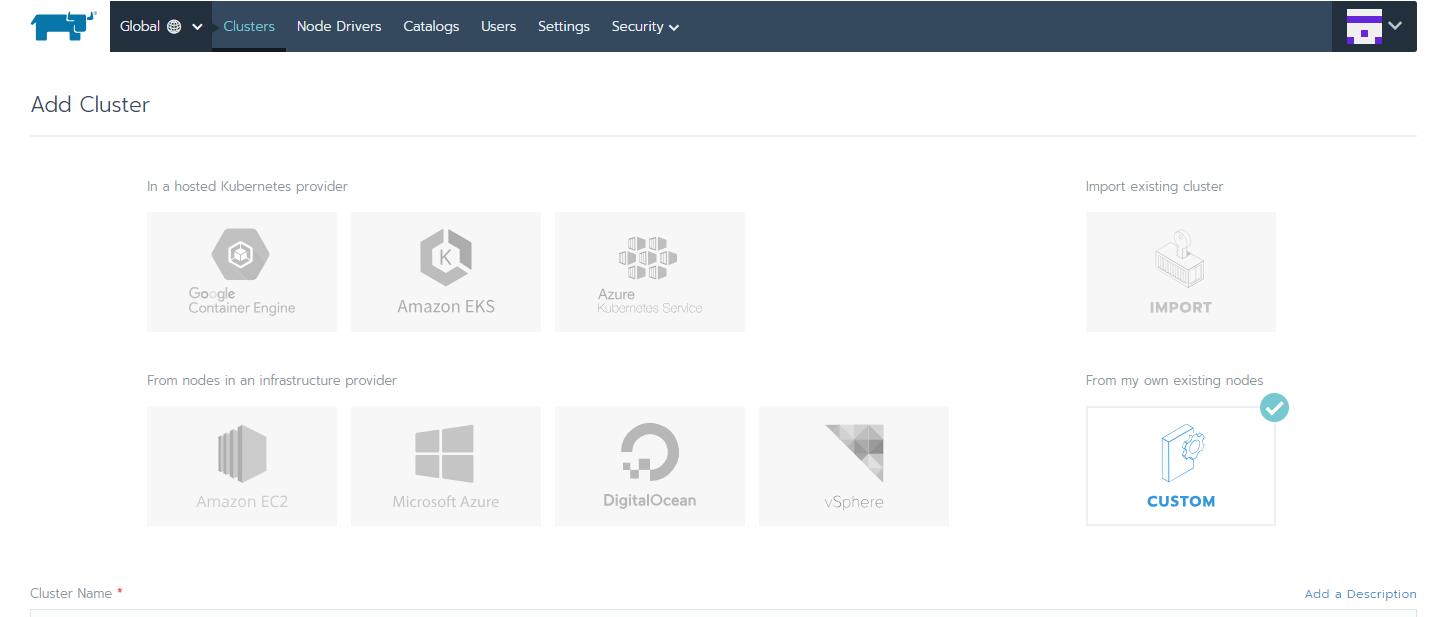
然后创建一个集群, 我这本机VM中运行, 所以选择了Custom. 输入完集群的基础配置之后, Rancher会提供另一条docker命令, 拿到节点上运行, 初始化过程是这样的:
- 每个执行的节点上, 创建一个叫rancher-agent的特权容器,
- 这个容器会继续创建rke-tools的容器, 然后用它来初始化容器的宿主机各个组件, 比如kubelet, kube-proxy, api-server等等
- 在rancher上会同步显示每个步骤的信息, 整个过程无需干预, 网络不是太差的话, 坐等10分钟集群就出来了.
Rancher接管集群的方式非常多样, 下图的上半部分是用于整合导入现有的Kubernetes集群, 下半部分是用于接管集群的初始化工作, 直接部署出来一套集群, 这样出来的Control Plane组件都是基于hypekube完全运行在docker中的(RancherOS也是这个思路, 整个操作系统全部容器化了)
平台从上而下分为多个层级, 每个层级的管理的粒度从粗到细, 一目了然
- Global 级别下管理各个集群整体配置, 全局设置, 用户和角色等
- Cluster 级别下管理节点及节点调度, 项目, 命名空间, 用户及权限, 存储, 单集群级别的监控预警/通知, kubectl接口等
- Project 级别主要功能是管理单个项目下各个命名空间的Kubernetes资源对象和项目成员, 包括运维管理最核心的功能
这是一个Global级别管理Role的例子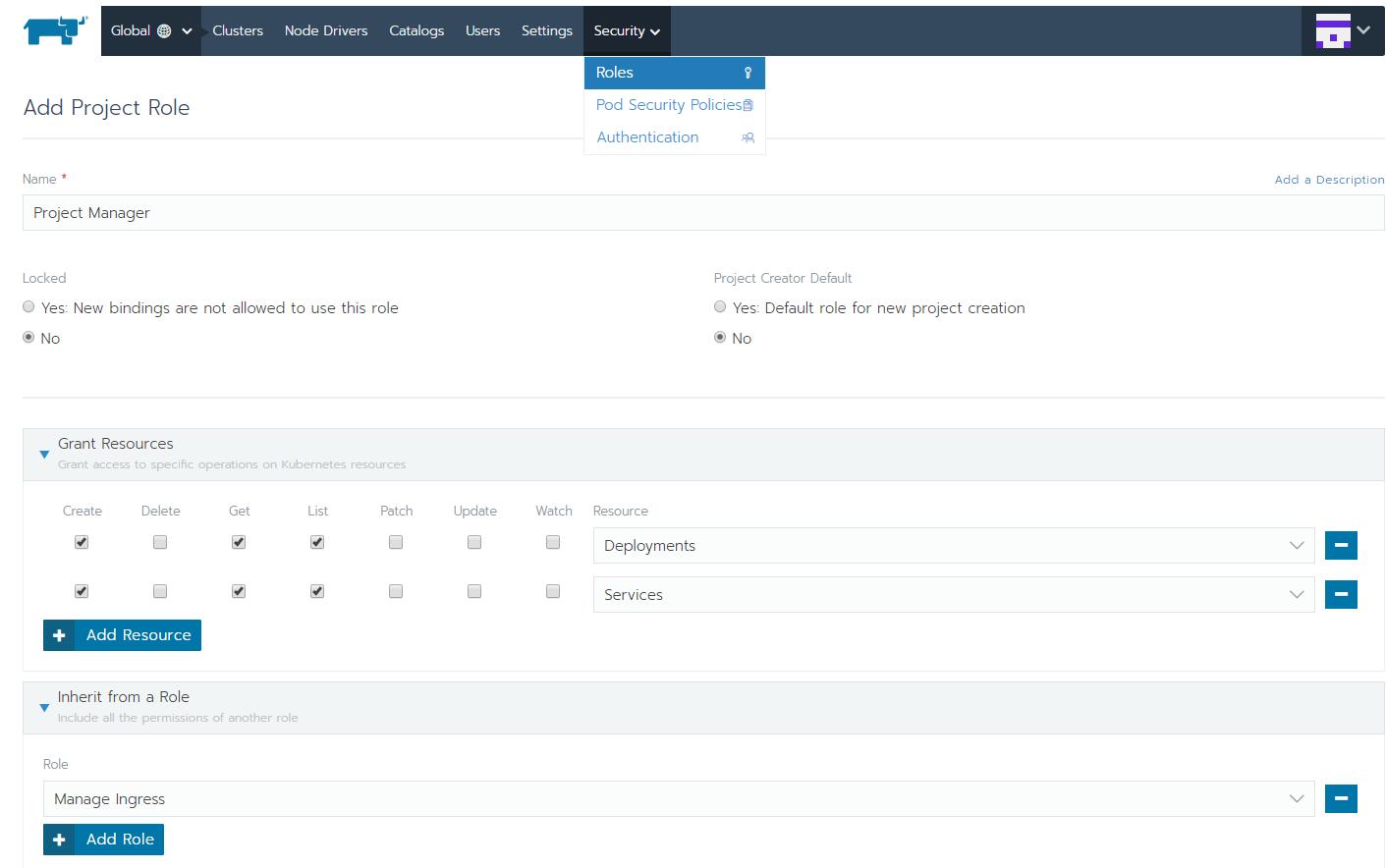
这是Cluster级别管理的概况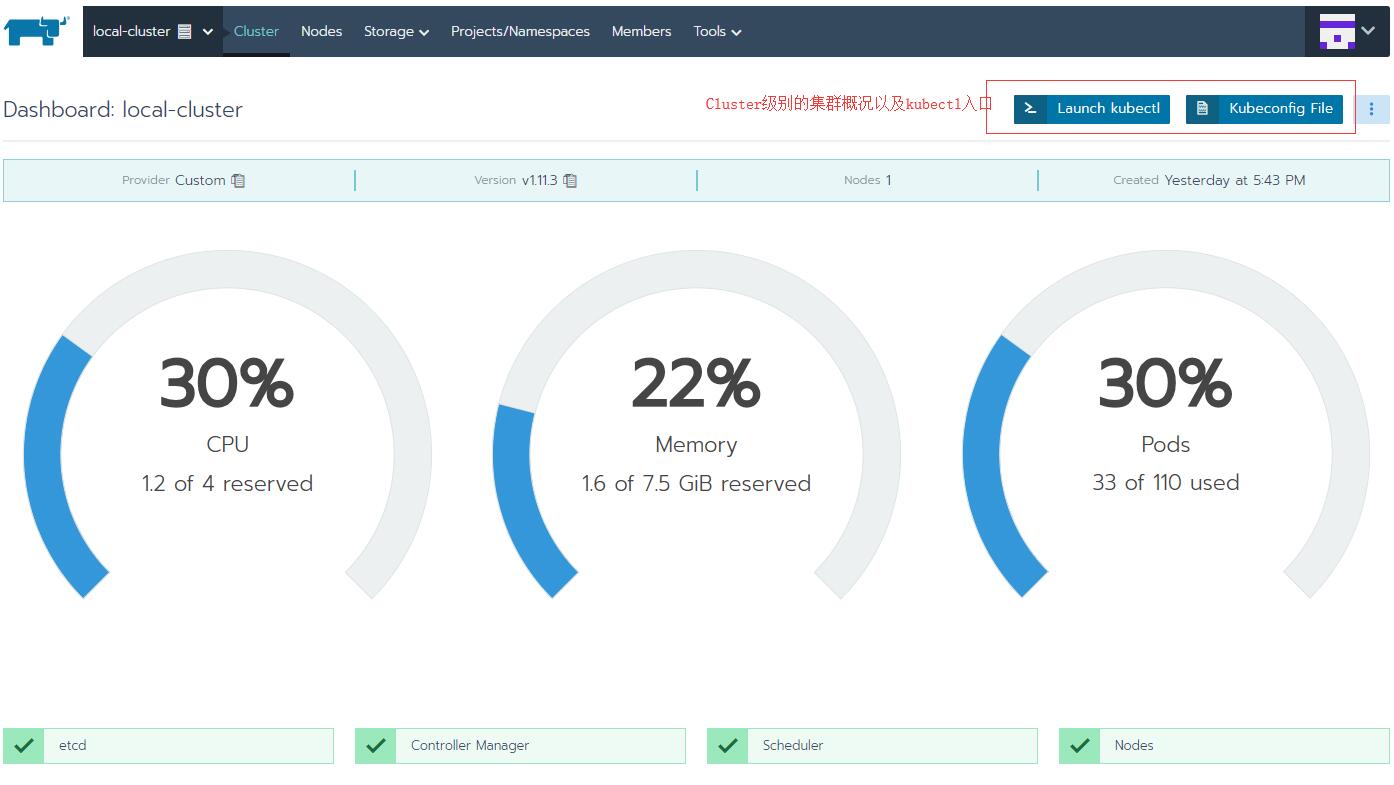
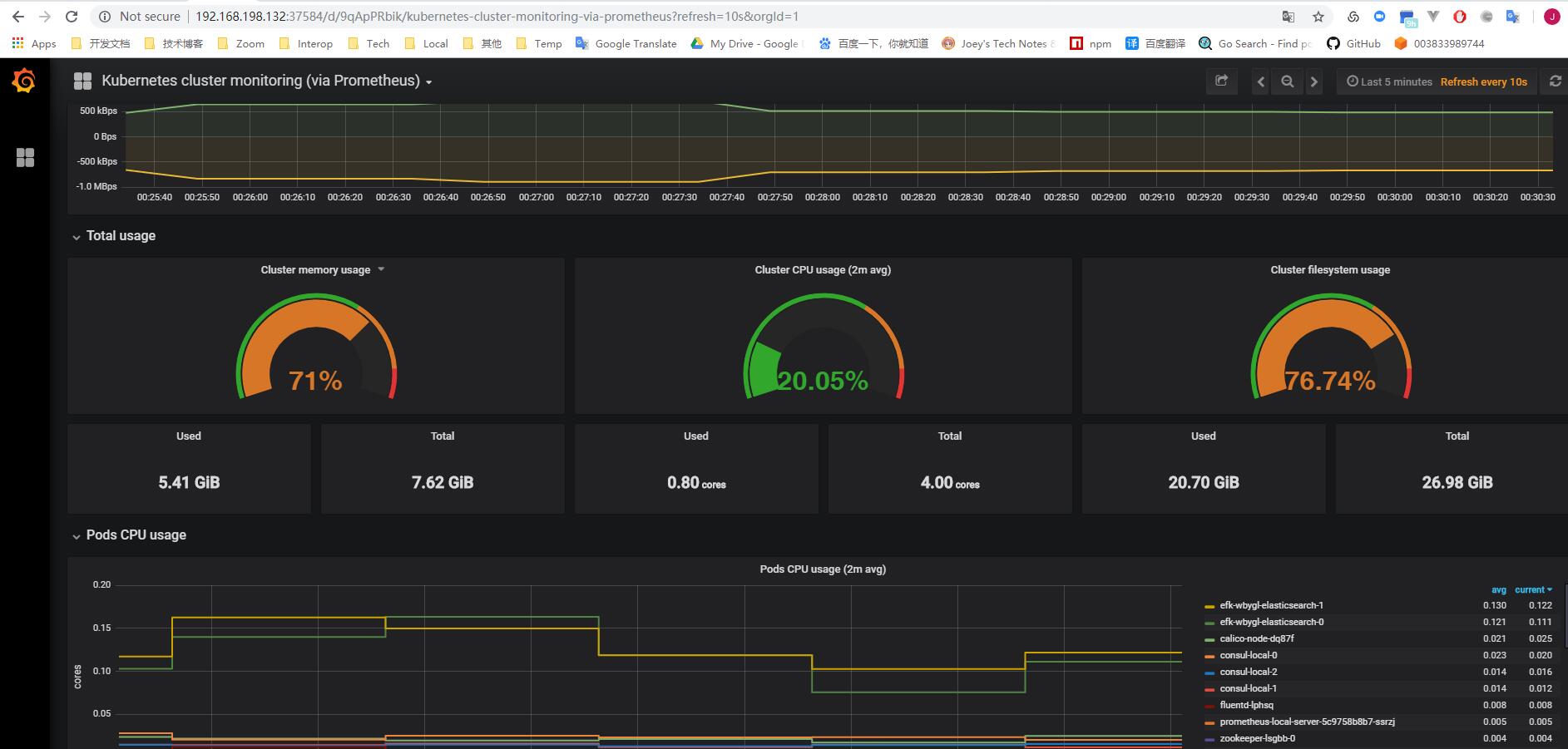
这是Cluster级别管理预警的例子, 预警条件和各种类型通知已经非常灵活了, 另外Cluster级别统一管理PV/StorageClass, 符合运维的场景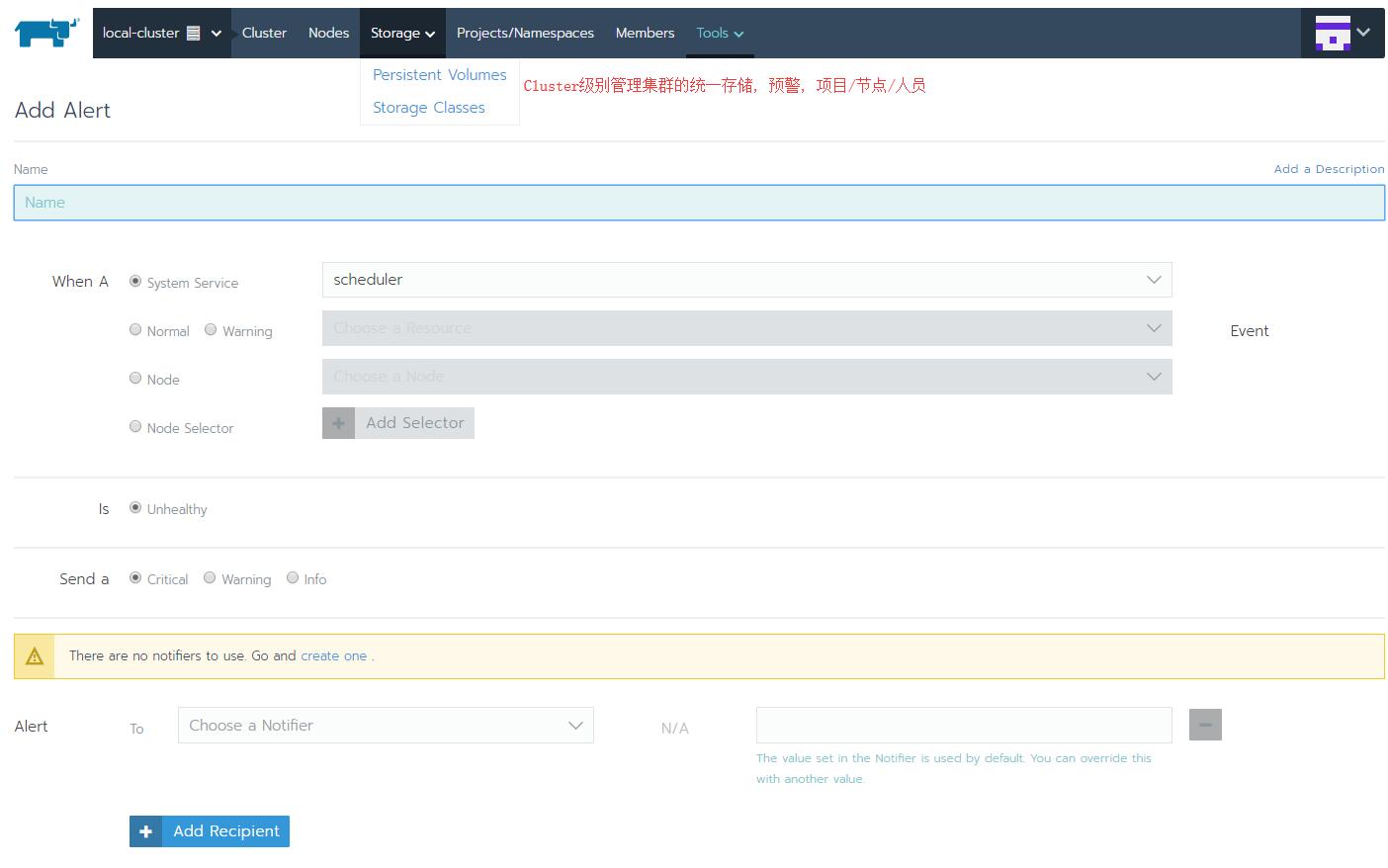
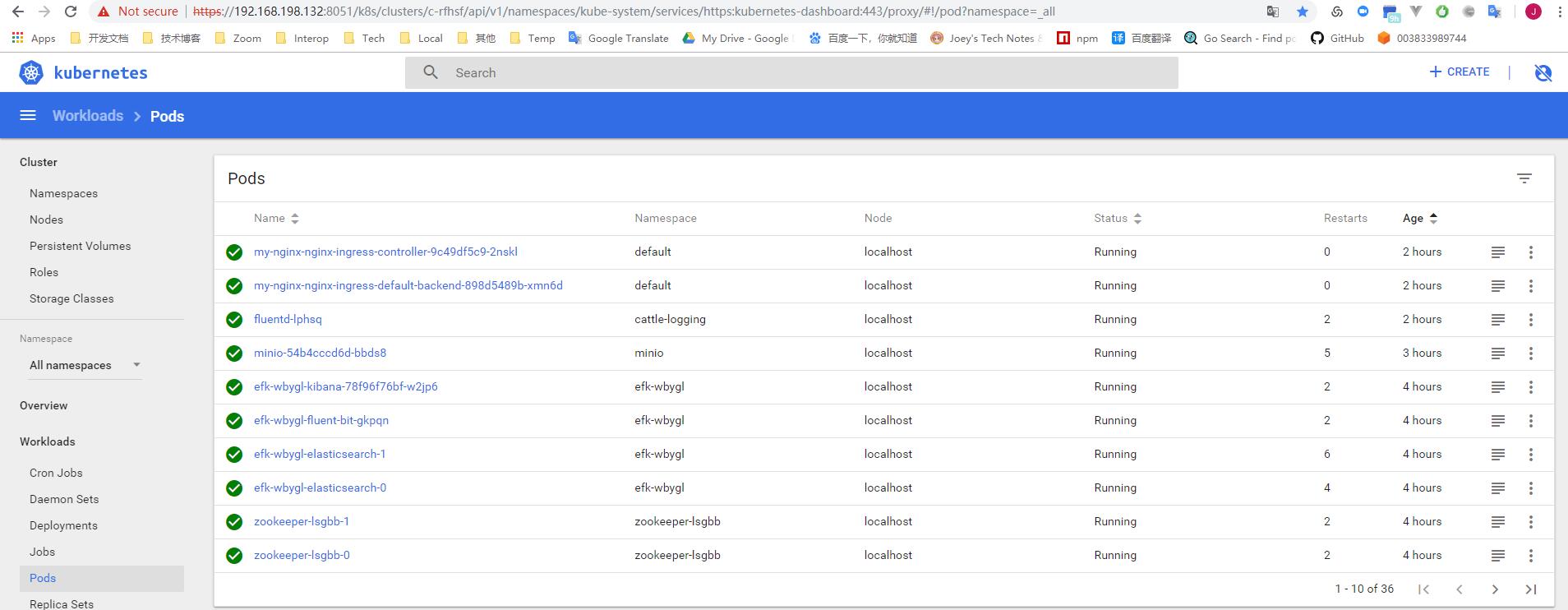
这是Project级别的工作负载情况, 有很多方便用户的细节设计. 对于每种Workload有方便的功能入口, 比如redeploy, rollback, scale, Endpoint链接, yaml编辑查看, shell到容器内部执行命令等.
每个workload, 也就是真正会产生Pod的资源, 展开都会有圆点和方块图标, 每个圆点代表一个container容器, Pod只有一个container的不会显示方块, 此时一个圆点也就是一个Pod, 对于有多个容器的Pod, 比如Init container或带有sidecar的, 会显示方块, 每个方块是一个Pod, hover上去有便捷的入口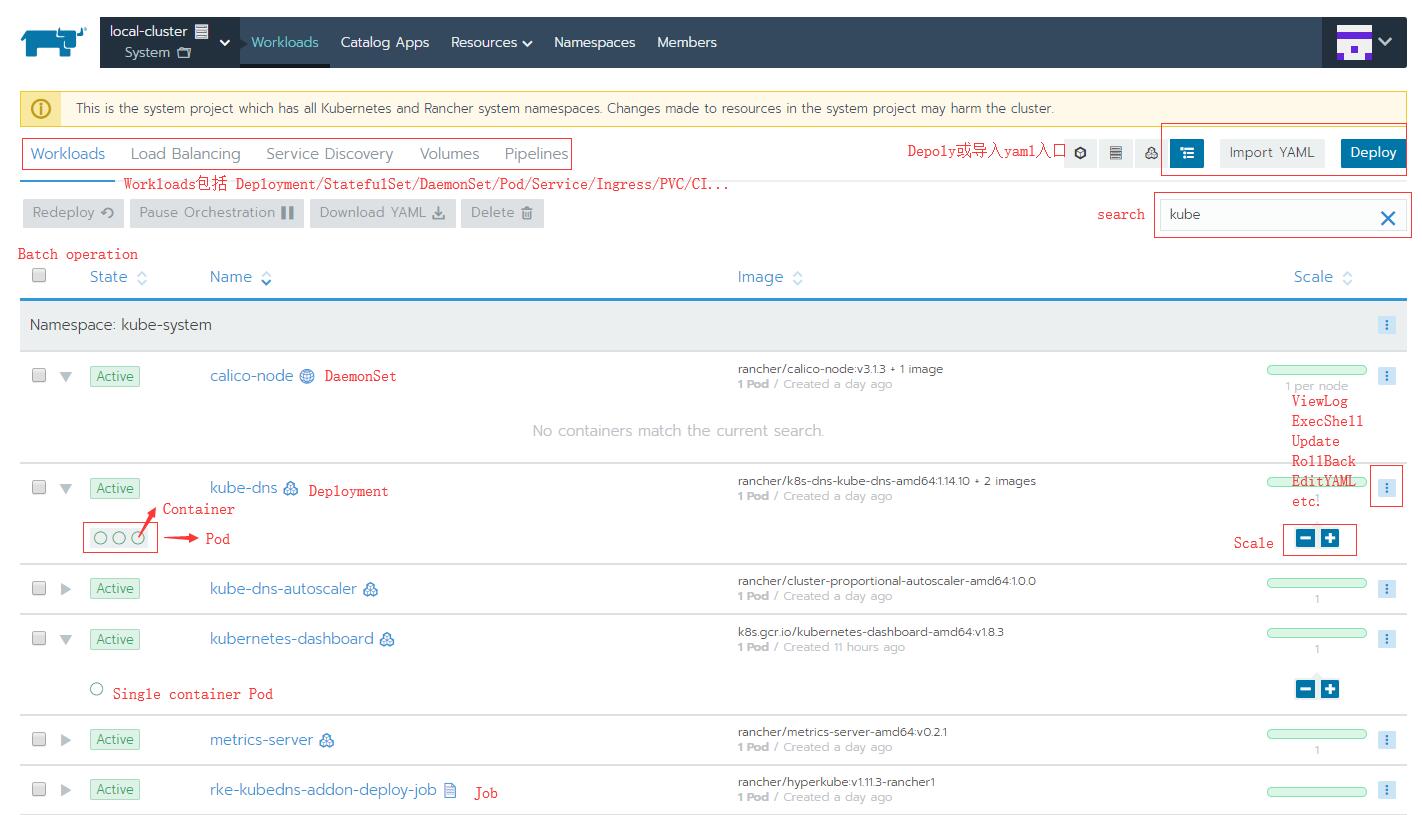
Project级别新建一个Deploy, 相当于deployment的语法糖, 直接表单配置很直观, 不懂Kubenetes也可以玩. 通过表单很方便的设置探针, 资源限制, Node Selector等, 而无需了解Kubernetes的语法结构 (感觉这是rancher的套路, 把功能做的很方便, 用户形成依赖之后不会搞原生kubernetes了, 然后出问题得找他们付费支持)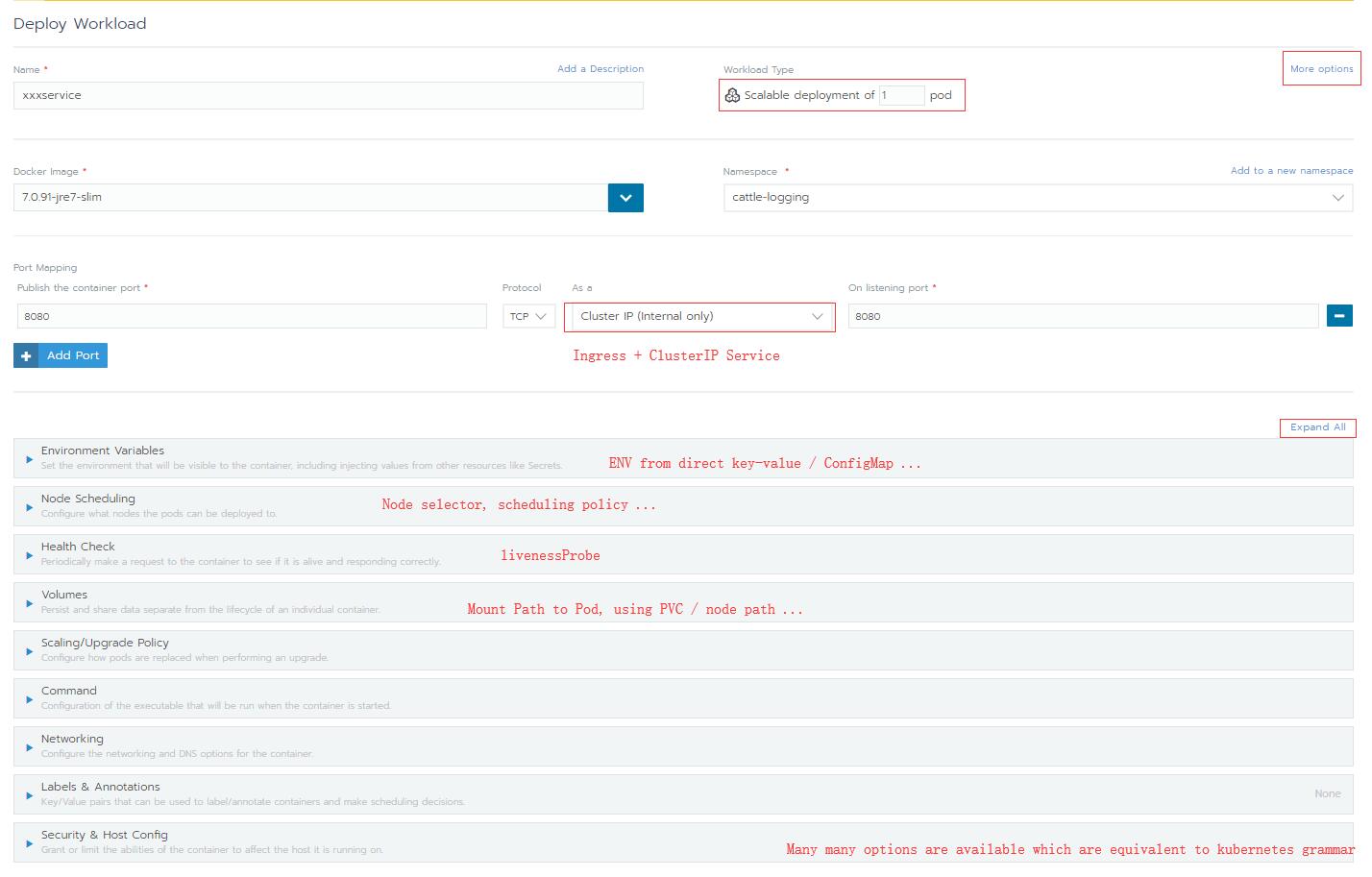
Pipeline功能, 以及其他Resource管理入口, 话不多说上图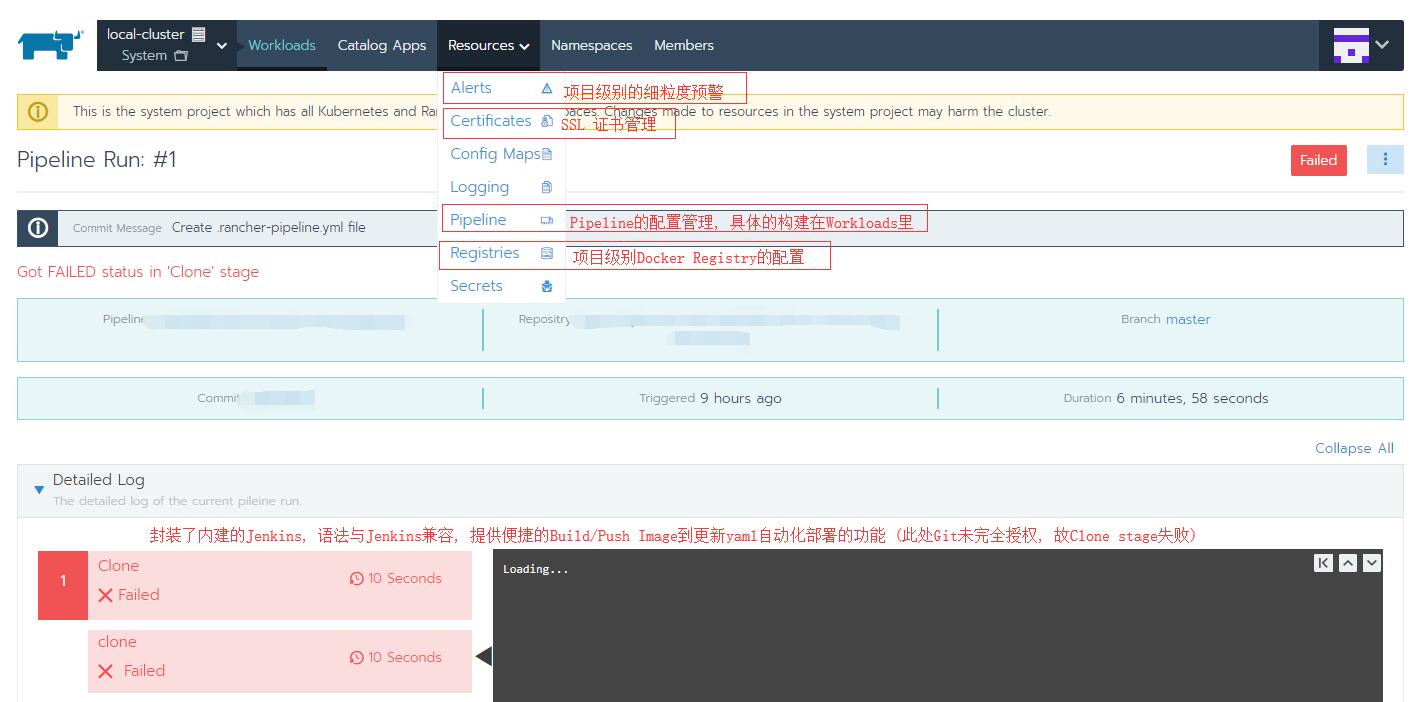
查看Pod日志, 以及完整的Yaml, 比Dashboard多了一下细节功能, 比如导出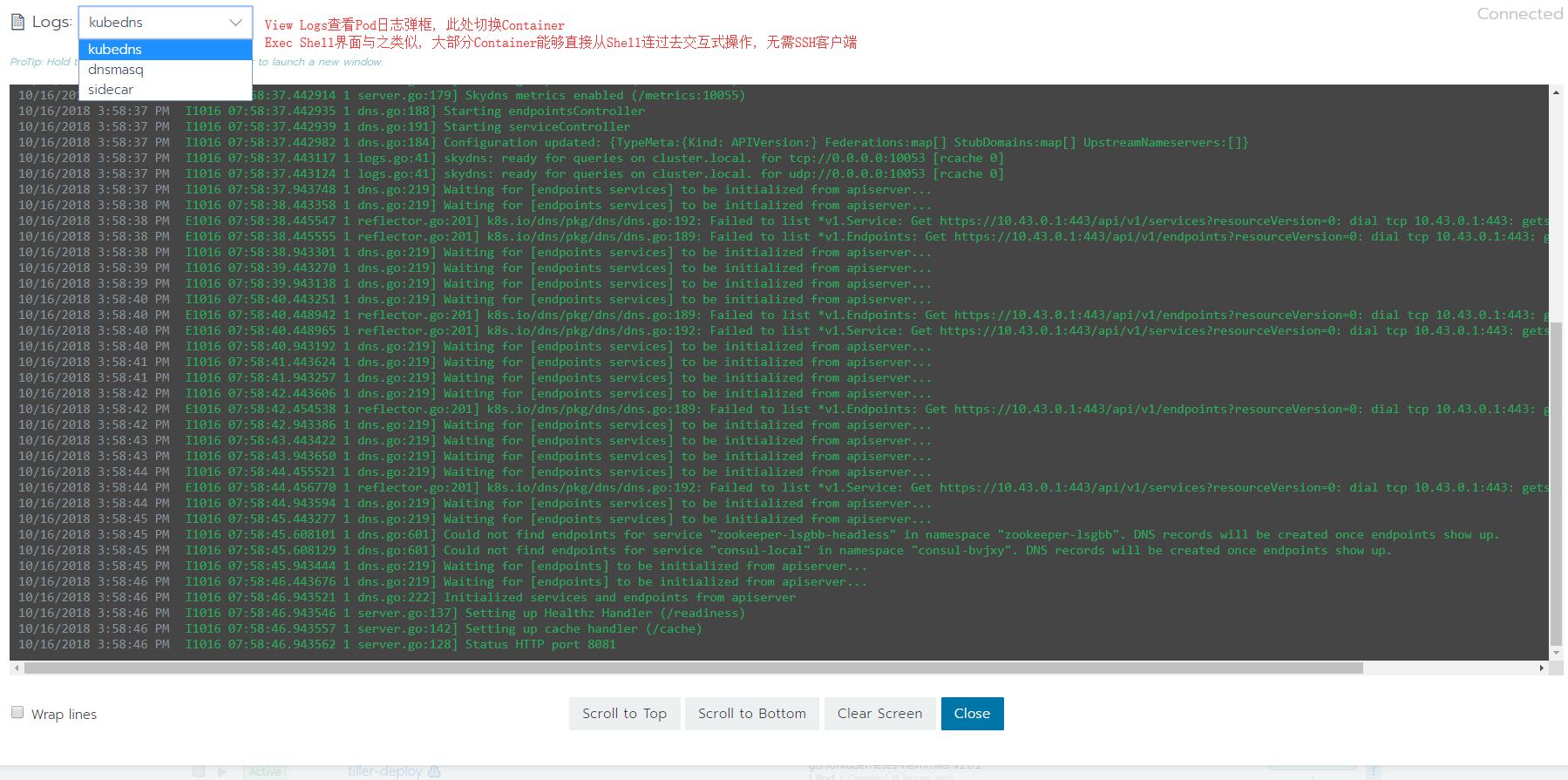
除了截图的这些功能, 还有一些重要的功能比如:
- 右上角用户可以管理kubectl登陆的Key和token
- Rancher自己整了一个Project的概念, 每个Project再分namespace, Member及其权限控制更符合真实场景
- Project级别下, 集成了运维的核心概念, 归纳一下,
- Workloads和Catalog App管理的是动态的资源, 真实的容器和服务
- Resource下管理的主要是相对变化较少的部署资源, 相对静态, 比如ConfigMap/Secret, 此外还有Pod/Depoloyment级别的预警配置, 以及日志集成等, 资源管理还有证书的管理, 能很方便的做SSL Ingress, SSL offloading等
- LoadBalancing 直观的展示的当前的Ingress和反向代理配置, 是对外可见的服务,
- Service Discovery 是内部的服务汇总, 包括集群内部分配的DNS以及固定的ClusterIP等, 是对内可见的服务
Rancher对Helm的支持
Helm 如今以及成为kubernetes集群必不可少的一个组件了, 包括一个客户端cli程序和一个服务端(Tiller镜像的Deployment), 每个应用声明为一个Chart, 通过动态模板隔离了配置和编排架构, 并且可以统一管理发布以及版本控制, 减少了大量的运维成本.
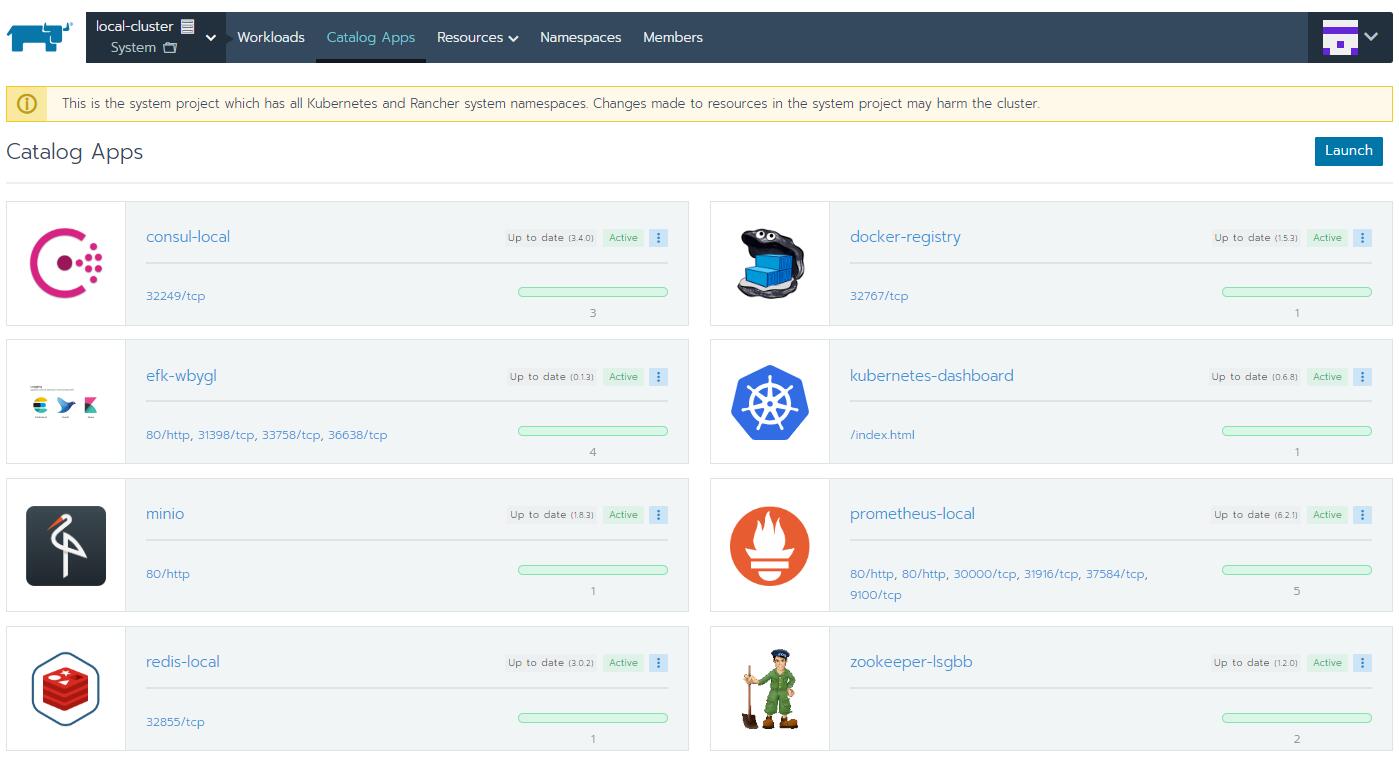
Rancher平台Catalog App的功能就是对Helm的集成, Global级别下点击Catalogs打开Helm Stable仓库可以获取到更多的Helm Chart, Helm Incubator不要开, 质量明显不如Helm Stable, 也可以添加自定义的Helm仓库. 然后, 在项目级别的Catalog App里, 可以Launch很多第三方Chart, 分分钟部署好集群基础设施.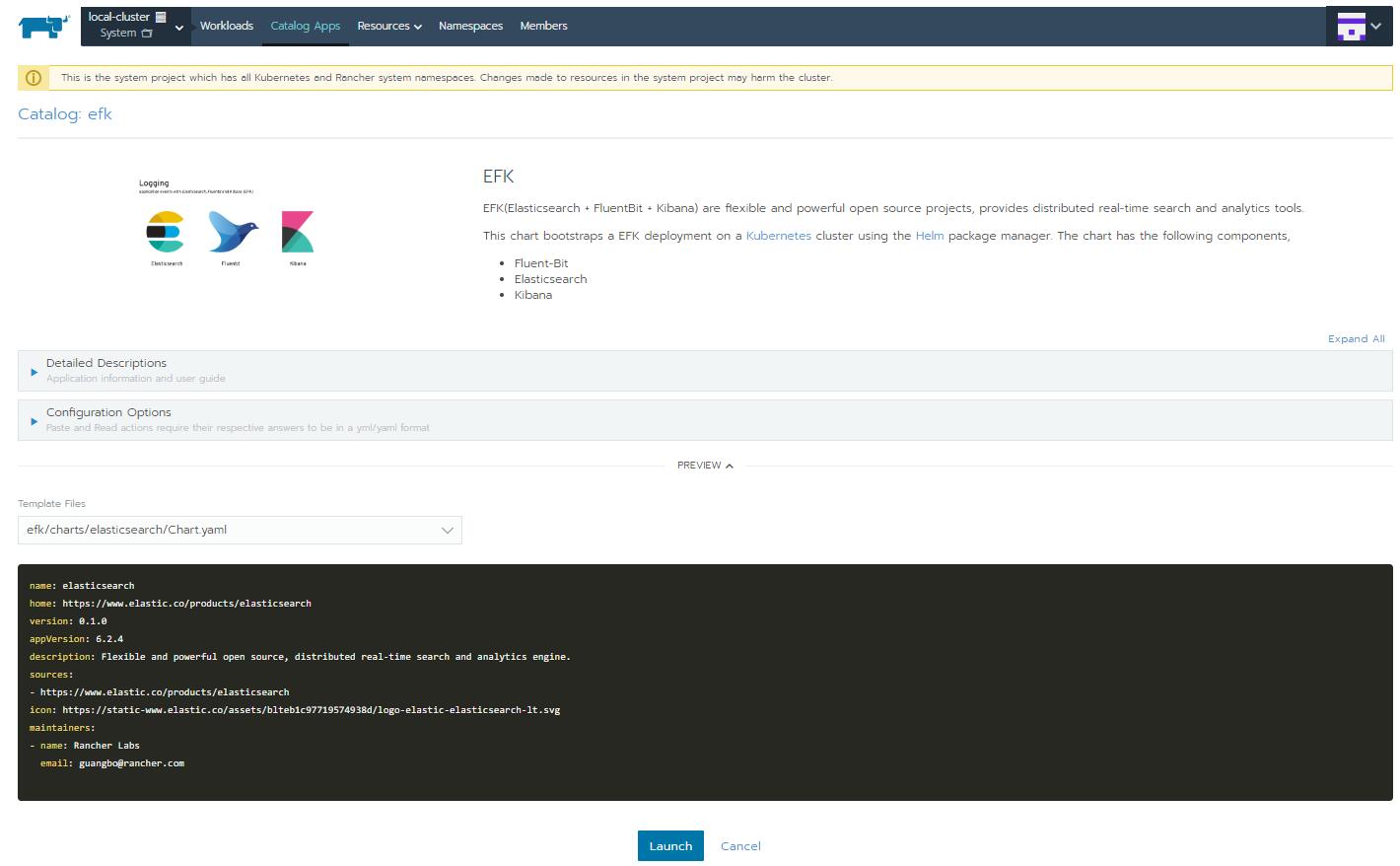
虽然Catalog App方便透顶, 但笔者以为重要的基础设施还是自行维护, helm install去创建比较好, 或者用第三方云服务商的现成的服务, 因为基础组件的稳定性和运维要求更高, 要么就吃透, 要么就不要自己维护, 用Rancher Launch一个哨兵模式Redis还好, 但是Launch一个EFK, 没有一定背景知识不一定可以完全理解, 出了问题就一脸懵逼了.
在RKE创建的Kubernetes(hypekube)集群下, 自己玩helm和别的一样,
- 客户端~/.kube/config 设置好context & user & cluster 与 kubectl 共享配置访问集群
下 - 在集群上先创建tiller作为serviceaccount, 用于管理helm相关的应用
- 下载helm客户端, init一下就完事了
- TLS双向认证的helm参考文档配置
1 | kubectl -n kube-system create serviceaccount tiller |
总结
试用过程中也发现了Rancher的一些局限性, 而且因为它以及Kubernetes不是很熟悉, 遇到了一些坑, 解决的办法以及心得在这里分享一下
- Rancher本身比较耗资源, 运行时占用>1G memory. 最好单独部署, 或运行容器时限制cpu和内存, 防止影响宿主机
- 如果用Rancher创建集群, Ingress Controller默认会帮我们创建好, 但Ingress Controller初始配置不一定是想要的(比如默认80端口且创建好后无法修改), 建议yaml自行维护Ingress Controller, 具体的Ingress配置可以在Rancher的UI中配, 很方便
- Workload里面StatefulSet的Scale按钮扩容没有提示, 一按就会修改StatefulSet开始调度, 慎点, StatefulSet一般都是像Redis, MySQL这种应用, 的权限控制应该要更严一点
- PV的信息最好加上Node Affinity, PVC加上Label Selector等, 防止PVC申请到错误的PV.
- Rancher使用目前没遇到大的问题, 小问题比如Catalog App状态更新的时候有延迟等
- 需要防止Pod调度导致其他Pod饿死的情况, 比如像ElasticSearch启动时非常占资源, 节点调度和资源限制策略需要注意, 比如用LimitRange控制单个资源, ResourceQuota控制整个namespace
- 集群调试方面, 如果Workload无法正常运行或不停的CrashBackoff, 有一些常见的调试方法如下:
- Kubernetes本身是否有报错, Rancher平台或Dashboard可以直接看到
- Container的log是否有error, 通过栈轨迹分析错误原因
- PVC绑定的PV, 对应的Path/Disk是否有读写权限等等
- 大部分常见问题能够在Rancher平台上直接定位, 但不排除比较难搞的问题还是需要kubectl v+日志级别 调试, kubectl describe查看资源状态
- 终极办法, 到节点上直接运行docker或其他运维命令, 这种比较底层的定位问题的方法能够直接看到进程和文件, 避免了”应用不知道被集群调度到哪去了”的不安全感~
最后来个用Rancher部署的Kubernetes集群基础组件全家福吧