[DevOps]《SRE:Google运维解密》读后感
引言
最近看了《SRE:Google运维解密》这本书,讲的是Google的天才们如何通过软件工程方法改变运维方式,保障超大型分布式系统的可靠性的。而这群人就是经验最丰富的Site Reliability Engineers,即最近 DevOps 大环境下比较热门的新职业 SRE。笔者已经很久没有遇到这种能一口气看完的书籍了,这些年本人各种勤杂工,临时工,消防员的经历,与书中很多地方都有强烈的共鸣,有种提壶灌顶的感觉,以至于忍不住想写一篇读后感,记录一下书中的经典语录和笔者个人的理解感受。
大型软件系统生命周期的绝大部分都处于“使用”阶段,而非“设计”或“实现”阶段,那么为什么我们却总是认为软件工程应该首要关注设计和实现呢?
这句话是书背面的第一句话,也是这句话引起了笔者的兴趣。作为一个软件开发者,我们很自然地对运维阶段和可靠性选择性失明,因为我们大部分精力关注在如何设计和实现了,即使在设计阶段考虑可用性,可伸缩性,性能,数据完整性等等各种质量属性,也肯容易陷入把这些非功能性的质量属性划到低于功能需求的较低优先级需求的误区中,在架构设计的权衡利弊上低估了Reliability的重要性。人们总是会说”先实现功能”,这句话就已经暴露了软件设计和开发人员的思维误区了。就如Google VP, SRE名词的创始人,Ben Treynor Sloss所说,“可靠性是任何产品设计中最基本的概念,任何一个系统如果没有人能够稳定的使用,就没有存在的意义”。
DevOps 与 SRE
Google 在全球构建了上千人的Site Reliability Engineer团队,融合了开发与运维,彻底解决了研发团队与运维团队的分歧和鸿沟。
可以说,DevOps 是 SRE 理念的普适版,SRE 是 Google 对于DevOps的具体实践,二者的核心理念是相通的。
第一章对研发与运维的矛盾根源的解释非常直白:研发部门想要“随时随地的发布新功能,没有任何阻拦”,而运维部门则想要“一旦一个东西在生产环境正常工作了,就不要再进行任何改动”。运维团队会列出一个非常长的检查清单,要求上线之前任何功能必须将所有以前的事故模拟一遍,开发团队吃过苦头后转为功能开关,增量更新,补丁化,这些名词的唯一目的就是绕过运维部门设立的各种流程。这种说法比较过激,但现实项目中确实有类似的感觉。
因为两个角色的关注点不同,对风险的定义不一致,为了维护各自的利益而产生矛盾。从根本上解决这样的矛盾就是让两个角色互相理解对方的思维和关注点,也就是需要开发和运维部门都要在思维上有所改变,在本职工作之上,从软件项目整体来思考。而SRE的目的就是寻求快速创新和高效运营之间的风险平衡,而不是简单的将服务在线时间最大化。
基本概念
书中提到了很多概念和名词,用来明确及量化一些可用性以及其他相关的属性。
风险容忍度
风险容忍度源于产品的商业目标,转化为工程目标,进而用于制定和量化性能和可靠性目标。简单来说就是量化系统挂了会带来多大的损失。波音飞机的Bug会导致坠机和乘客伤亡,风险容忍度就是0;提供企业服务的产品会一般比提供ToC产品的服务风险容忍度更低。
服务质量指标 SLI
Service-Level Indicator,可以理解为可度量的关键监控指标,可用性,延迟,错误率,吞吐量等等,这些指标度量了服务质量。
服务质量目标 SLO
Service-Level Objective,定义关键指标的预期目标,如99%的响应延迟<100ms。如果SLI的真实数据超过了定义的预期SLO,甚至可以主动制造可控的故障,见中文版36页的”Chubby服务计划内停机“。SLO不需要定义的太高,造成成本过高或是服务极其稳定的假象,可以对外定义稍低的目标,对内定义较高的目标,来留出一定的安全缓冲区。
服务质量协议 SLA
Service-Level Agreement,是指跟用户达成的协议,是法律上与用户的协议条款,比如没有达到SLO的99.99%可用性会赔多少钱,这就是SLA。Google的GSuite的SLA写道:如果每个月的可用性没有达到99.9%,按照不可用时间赔偿Service Credit,也就是免费续用多少天;而Google的CDN和Cloud Storage这些业务定义的SLA是月度没达到99.95%则赔偿。
错误预算
基于SLO计算出来的在某段时间还能容忍多久的故障,用这个具体的数字来决定是否可以在生产环境发布。
举例来说,比如上个季度一次可没有事故发生,那么在99.99%可用性的SLO下,还有12.96分钟的故障时间可以“挥霍”,并且这个时间足够发现事故并回滚变更,那么就允许一次全量发布。用数字说话来避免部门间的“谈判“和“博弈“,比如开发和销售部门想上线、运维部门不给上线这种情况的撕X。
MTTF & MTTR
平均失败时间和平均恢复时间,当事故真的发生时,平均失败时间用于计算可用性SLO是否达标;平均恢复时间用来评价事故应急能力,量化处理故障的效率。
SRE思维
本节摘录了一些书中一些一针见血的SRE理念。以原书经典内容为标题,加上了一些笔者的理解和现实经历,从这些Google工程师简短朴实的原话中窥一斑而见全豹,理解SRE技术和管理思维。
如果系统正常运转中需要人工干预,应该将此视为一种Bug
- DevOps和SRE的核心理念之一就是自动化任何可以自动化的事情,尽可能的减少琐事,这样SRE或者运维才有精力去关注和优化整个工程,而不是做重复的或者无聊的琐事。SRE团队定了50%的上限,每个人必须有50%以上的时间用在软件开发或者其他有突破性价值的工作上
- 现实案例:Kubernetes以及其在Google的前身Borg把服务扩容做到了自动化,Prometheus以及Google的Borgmon把监控做到了自动发现自动监控都是成功案例
简化,直到不能再简化
这句话是针对监控和报警的,当然也适用于其他方面,这一小节我们也只关注监控预警的设计思路。
- “复杂是没有止境的,如果我们只能监控4个指标,就是延迟,流量,错误,饱和度”。
- 笔者曾一度认为监控预警多多益善,在故障时有足够的信息来找到根源问题,然而Google的做法颠覆了这个观念:在底层适当添加一些白盒监控的详细指标,在高层采用黑盒监控去监控真正对用户有影响的关键指标,避免虚警和过多监控数据造成根源误判。紧急警报应该关注于现象,而非试图在报警信息中推断原因。
可靠性只有靠最大程度的简化不断追求而得到
- 与上一条一样,越简单的东西越不会出错,分布式系统每增加一个组件,可靠性是指数级下降的。应该避免过度设计,简化组件数量和每个组件的复杂度,这带来的收益远比架构师庞大工整的设计图有用。
- 顺便看了下NoCode项目(也是一名Google工程师的杰作),已经快3万星星了:The best way to write secure and reliable applications. Write nothing; deploy nowhere.
- 话说回来,软件本身的复杂度不可避免,但是通过把负代码行作为一个绩效指标,最小API原则来减缓复杂度的增长。相信每个开发工程师都经历过把某些代码删除,一切就恢复正常了的经历,反正笔者有很多这样的经历,最喜欢的事情之一就是删代码。
理解一个系统如何工作并不能使人成为专家,只能靠调查系统为何不能正常工作才行
- “系统正常,只是改系统无数异常情况下的一种特例”,而解决故障是技术成长的”捷径“
- 笔者对这一点感触颇深,这几年技术成长最快的时候,不是开发或维护软件系统写了很多代码的时候,是那些痛苦的救火经历。比如之前有一次核心业务支撑不了百万级数据并发写入,从业务代码到数据库做性能优化的经历,让笔者对并发编程和数据库知识有了质的提升;而最近解决了某个项目非常隐蔽的Socket泄露问题带来的对网络传输层的理解超过了一个学期的课程。解决故障从来不是靠猜,靠搜索引擎,而是通过推理、编码、测试、验证,才能找到那些藏在深处的问题根源。纸上得来终觉浅,绝知此事要躬行。
东西早晚要坏的,这就是生活
- 这本书贯穿全书的思想就是故障一定会发生,而且大部分情况下是以没有人能预料的方式发生。因此我们需要:提前做故障演练,事先准备好应对措施,使用正确的方法论处理故障(第11到16章都是在阐述如何正确应对故障),并做好事后总结。
- 这句话其实与墨菲定律等价,概率论告诉我们:假设某意外事件在一次实验(活动)中发生的概率为p(p>0),则在n次实验(活动)中至少有一次发生的概率为P=1-(1-p)^n。由此可见,无论概率p多么小(即小概率事件),当n越来越大时,P越来越接近1
- 业界有Netflix这样疯狂的公司在产线跑Chaos Monkey,最近阿里也官宣了Chaos Blade,可见在微服务大潮下,**混沌工程的重要性。大家意识到了故障的必然性,索性人为制造故障,强迫应用软件必须能够在随时故障的环境下提供可靠的服务**。
如果你还没有亲自试过某件东西,那么就假设它是坏的
- 这句话是第17章的引言,说明了测试的重要性。测试是工程师提高可靠性投入回报比最高的一种手段。测试驱动开发(TDD)这个词出现很久了,但是落到实处的却不多。大部分软件开发者,包括笔者自己,都没有意识到测试带来的巨大回报。单元测试,压力测试,集成测试,端到端测试等等自动化测试用例和测试代码的编写,带来的是随着时间增长指数级增长的回报,因为这些自动化测试不是运行一次,每天都可以运行,而且时间越长,软件复杂度越高的情况下,带来的收益将远超编写测试的时间成本。
- 人总是倾向贪婪算法获取短期利益,很难意识到风险其实是最昂贵的,一旦发生事故,带来的损失甚至是无法用金钱衡量的。建立强测试文化很难,但值得去做。
多样化的团队可以避免设计盲点
- SRE是需要开发自动化运维相关系统的,而开发团队的组建Google也给出了最佳实践:合并通用型人才(generalist)和领域专家(specialist)构建种子团队。
- 通用型人才可以很快开始工作,而资深领域专家可以提供更广阔的知识和经验。
将所有鸡蛋放在一个篮子里是引来灾难的最好办法
- 这句话讲的是负载均衡以避免单点故障。分布式系统要保障可靠性,必须没有任何一个单点故障源。墨菲定律告诉我们可能故障的地方,一定会故障。从光纤链路的冗余,网络路由自适应,到前后端的负载均衡,基于共识算法存储一致性的数据,最主要的原因就是避免单点故障。
如果请求没有成功,以指数型延迟重试
- 在重试机制方面,开发者倾向简单的策略,而不是稍复杂一点Exponential Back-off Retry,然而从可靠性分析来看,这可能是致命的问题,不断的错误重试可能触发正反馈循环,导致系统过载,甚至连锁故障,指数型延迟重试,可以避免在出现短暂过载或非致命故障时,发生连锁反应。举个例子来说,一个Java应用服务可能一开始只是负载较高,触发了比较频繁的GC,但期间失败或超时的请求不断重试会加剧负载,GC更加频繁,导致重试更多,最终触发GC死亡螺旋,导致系统崩溃。
- 关于如何避免过载和连锁故障,在第22章有很多深入技术细节的讨论,见中文版260页。笔者印象最深刻的一次连锁故障就是调用 Redis 的 KEYS 导致业务停滞和缓存击穿,本质上还是BUG导致系统资源不足和关键组件过载,而客户端并未降级,还是以固定频率发送请求,血淋淋的教训啊。
- 另外,分布式系统很容易出现惊群效应导致资源白白浪费甚至系统过载,这在第24章分布式周期性任务中有一些相关讨论非常有借鉴意义,比如分离Workflow状态到一致性存储,无状态幂等的Job等。
很多分布式系统的问题最后都归结为分布式共识问题的不同变种
- 看到这句话才意识到,分布式锁,强一致存储,复制状态机(RSM),可靠的消息队列,其实本质是一样的,归结于CAP的取舍,为了让不同节点的数据达成共识,比如RDBMS为了事务ACID而取CA,而NoSQL只提供BASE而取AP或CP,他们在分布式部署时的本质都是RSM
最好的数据完整性保障手段一定是多层的,多个保障手段彼此覆盖
- 这也是书中多次提到的”纵深防御“策略,数据完整性也是软件设计阶段容易忽视的一个属性,而恰巧这对用户来说通常是最重要的属性之一,没有用户可以容忍自己的数据平白无故消失了。
- 纵深防御的常用多层防御策略有:软删除,备份和恢复,数据复制和冗余等等,这些策略适用于应用软件,操作系统和硬件层面。举例来说,就是不能因为有RAID机制而不去做应用层的数据复制,不能因为有定期备份而不做软删除。看到这里笔者悄悄地给检查了一下最近一个新项目的数据库设计,给几个关键表加上了“deleted tinyint(1)”字段。
忘记过去的人必然会犯同样的错误
这句话是在书中是在故障演练和事后总结这一部分提到的,SRE需要牵头演练过去发生的和以后可能发生的故障。
- SRE需要把故障演练以及事后总结作为工作的一部分,每年或每个季度在非生产环境,甚至部分故障容忍度稍高的生成环境上,演练故障和恢复流程。既然故障一定会发生,那么是接受一次可控的演习故障发现潜在问题,还是在半夜慌忙处理真实发生的故障呢?
- 故障演习的好处太多,但不代表真实故障不会发生,对于真实发生的故障,每一次故障都是非常宝贵的经验,应该重视事后总结,并互相学习这些事故。这一点非常佩服 Google 的SRE们,在书中毫不避讳地分享了很多真实的大规模产线故障,以及透彻事后总结分析。
一次中断性任务需要进行两次上下文切换,而这种切换会造成数个小时的生产力丧失
- 这是一条管理方面的观念:管理者需要意识到人的优势和劣势,人的效率不是稳定的。从人的心理学角度来看,人进入Flow State可以提升生产力,甚至艺术创造性,这就是专注的力量。而中断性任务,也就是各种会议,工单,临时事务,他人咨询和技术讨论等等,造成的上下文切换,会导致效率的成倍降低。这也是当前一些开发者抱怨白天干不了活,晚上加班干活效率才高的原因。而SRE兼职运维角色,必然有工单,常规运维负载等等中断性任务,很容易陷入低效循环中。
- Google解决这一问题的办法就是,极化时间,合理的轮值机制和琐事度量。极化时间是和轮值轮岗相辅相成的,比如今天某人专职负责处理工单和常规运维,代表参加其他团队的会议等等,明天专注X自动化运维系统的开发,由其他成员负责这些事情。当然这对团队成员的能力要求会更高,更彻底的做法就是尽可能减少这些“琐事”。
永远不要在正在运行的系统上做改动
- 这句话的语境是在说金丝雀测试和灰度发布,也可以叫“渐进式发布”,Google有专门的发布协调工程师(LCE)负责软件发布,以及量化计算的灰度比例。在生产环境上直接全量修改版本或配置,无异于直接制造灾难。
- 在部署变更和灰度控制过程中,有一个非常重要的概念,“跛脚鸭状态”,即不接受新的请求,处理完当前的任务即下线。跛脚鸭效应这个词源于政界的换届选举,用来描述应用服务的优雅退出可以说是非常形象了。
总结
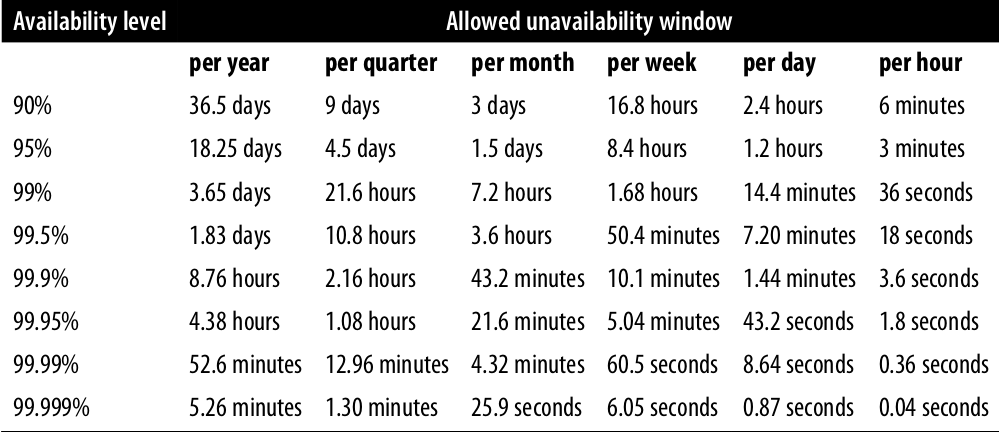
这本书从思维,技术,协作,管理等各个方面剖析了软件的可靠性,传统的开发人员和运维人员往往跳不出自己的职业思维,读完这本书后可以从整体上来看待软件生命周期。开发,测试,运维,管理者去看,都会有不同的收获。附一张系统可用性时间表: