软件设计杂谈——性能优化的十种手段(中篇)
索引
引言
上一篇,我们总结了六种普适的性能优化方法,包括 索引、压缩、缓存、预取、削峰填谷、批量处理,简单讲解了每种技术手段的原理和实际应用。在开启最后一篇前,我们先需要搞清楚:在程序运行期间,时间和空间都耗在哪里了?
时间都去哪儿了?
人眨一次眼大约100毫秒,而现代1核CPU在一眨眼的功夫就可以执行数亿条指令。
现代的CPU已经非常厉害了,频率已经达到了GHz级别,也就是每秒数十亿个指令周期。
即使一些CPU指令需要多个时钟周期,但由于有流水线机制的存在,平均下来大约每个时钟周期能执行1条指令,比如一个3GHz频率的CPU核心,每秒大概可以执行20亿到40亿左右的指令数量。
程序运行还需要RAM,也可能用到持久化存储,网络等等。随着新的技术和工艺的出现,这些硬件也越来越厉害,比如CPU高速缓存的提升、NVMe固态硬盘相对SATA盘读写速率和延迟的飞跃等等。这些硬件具体有多强呢?
有一个非常棒的网站“Latency Numbers Every Programmer Should Know”,可以直观地查看从1990年到现在,高速缓存、内存、硬盘、网络时间开销的具体数值。
https://colin-scott.github.io/personal_website/research/interactive_latency.html
下图是2020年的截图,的确是“每个开发者应该知道的数字”。
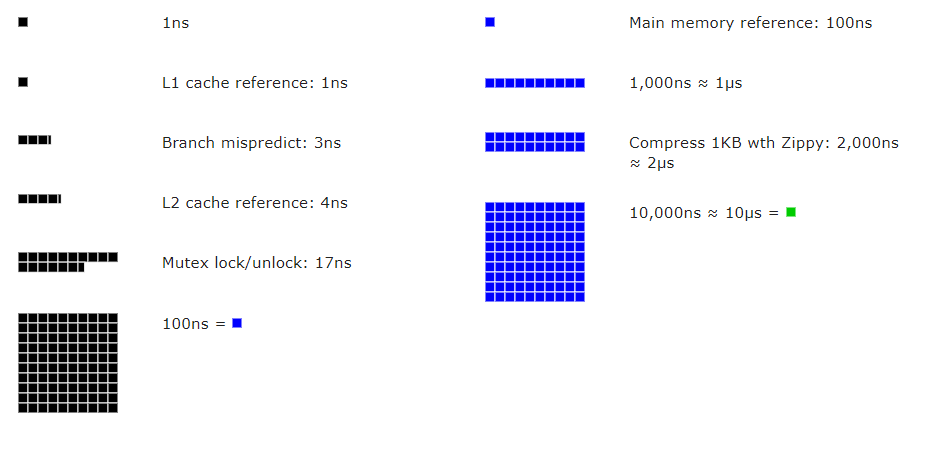

这里有几个非常关键的数据:
- 存取一次CPU多级高速缓存的时间大约1-10纳秒级别;
- 存取一次主存(RAM)的时间大概在100纳秒级别;
- 固态硬盘的一次随机读写大约在10微秒到1毫秒这个数量级;
- 网络包在局域网传输一个来回大约是0.5毫秒。
看到不同硬件之间数量级的差距,就很容易理解性能优化的一些技术手段了。
比如一次网络传输的时间,是主存访问的5000倍,明白这点就不难理解写for循环发HTTP请求,为什么会被扣工资了。
放大到我们容易感知的时间范围,来理解5000倍的差距:如果一次主存访问是1天的话,一趟局域网数据传输就要13.7年。
如果要传输更多网络数据,每两个网络帧之间还有固定的间隔(Interpacket Gap),在间隔期间传输Idle信号,数据链路层以此来区分两个数据包,具体数值在链接Wiki中有,这里截取几个我们熟悉的网络来感受一下:
- 百兆以太网: 0.96 µs
- 千兆以太网:96 ns
- 万兆以太网:9.6 ns
不过,单纯看硬件的上限意义不大,从代码到机器指令中间有许多层抽象,仅仅是在TCP连接上发一个字节的数据包,从操作系统内核到网线,涉及到的基础设施级别的软硬件不计其数。到了应用层,单次操作耗时虽然没有非常精确的数字,但经验上的范围也值得参考:
- 用Memcached/Redis存取缓存数据:1-5 ms
- 执行一条简单的数据库查询或更新操作:5-50ms
- 在局域网中的TCP连接上收发一趟数据包:1-10ms;广域网中大约10-200ms,视传输距离和网络节点的设备而定
- 从用户态切换到内核态,完成一次系统调用:100ns - 1 μs,视不同的系统调用函数和硬件水平而定,少数系统调用可能远超此范围。
空间都去哪儿了?
在计算机历史上,非易失存储技术的发展速度超过了摩尔定律。除了嵌入式设备、数据库系统等等,现在大部分场景已经不太需要优化持久化存储的空间占用了,这里主要讲的是另一个相对稀缺的存储形式 —— RAM,或者说主存/内存。
以JVM为例,在堆里面有很多我们创建的对象(Object)。
- 每个Object都有一个包含Mark和类型指针的Header,占12个字节
- 每个成员变量,根据数据类型的不同占不同的字节数,如果是另一个对象,其对象指针占4个字节
- 数组会根据声明的大小,占用N倍于其类型Size的字节数
- 成员变量之间需要对齐到4字节,每个对象之间需要对齐到8字节
如果在32G以上内存的机器上,禁用了对象指针压缩,对象指针会变成8字节,包括Header中的Klass指针,这也就不难理解为什么堆内存超过32G,JVM的性能直线下降了。
举个例子,一个有8个int类型成员的对象,需要占用48个字节(12+32+4),如果有十万个这样的Object,就需要占用4.58MB的内存了。这个数字似乎看起来不大,而实际上一个Java服务的堆内存里面,各种各样的对象占用的内存通常比这个数字多得多,大部分内存耗在char[]这类数组或集合型数据类型上。
堆内存之外,又是另一个世界了。
从操作系统进程的角度去看,也有不少耗内存的大户,不管什么Runtime都逃不开这些空间开销:每个线程需要分配MB级别的线程栈,运行的程序和数据会缓存下来,用到的输入输出设备需要缓冲区……
代码“写出来”的内存占用,仅仅是冰山之上的部分,真正的内存占用比“写出来”的要更多,到处都存在空间利用率的问题。
比如,即使我们在Java代码中只是写了 response.getWriter().print(“OK”),给浏览器返回2字节,网络协议栈的层层封装,协议头部不断增加的额外数据,让最终返回给浏览器的字节数远超原始的2字节,像IP协议的报头部就至少有20个字节,而数据链路层的一个以太网帧头部至少有18字节。
如果传输的数据过大,各层协议还有最大传输单元MTU的限制,IPv4一个报文最大只能有64K比特,超过此值需要分拆发送并在接收端组合,更多额外的报头导致空间利用率降低(IPv6则提供了Jumbogram机制,最大单包4G比特,“浪费”就减少了)。
这部分的“浪费”有多大呢?下面的链接有个表格,传输1460个字节的载荷,经过有线到无线网络的转换,至少再添120个字节,**空间利用率<92.4%**。
https://en.wikipedia.org/wiki/Jumbo_frame
这种现象非常普遍,使用抽象层级越高的技术平台,平台提供高级能力的同时,其底层实现的“信息密度”通常越低。像Java的Object Header就是使用JVM的代价,而更进一步使用动态类型语言,要为灵活性付出空间的代价则更大。哈希表的自动扩容,强大的反射能力等等,背后也付出了空间的代价。
再比如,二进制数据交换协议通常比纯文本协议更加节约空间。但多数厂家我们仍然用JSON、XML等纯文本协议,用信息的冗余来换取可读性。即便是二进制的数据交互格式,也会存在信息冗余,只能通过更好的协议和压缩算法,尽量去逼近压缩的极限 —— 信息熵。
结语
理解了时间和空间的消耗在哪后,还不能完全解释软件为何倾向于耗尽硬件资源。有一条定律可以解释,正是它锤爆了摩尔定律。
它就是安迪-比尔定律。
“安迪给什么,比尔拿走什么”。
安迪指的是Intel前CEO安迪·葛洛夫,比尔指的是比尔·盖茨。这句话的意思就是:软件发展比硬件还快,总能吃得下硬件。20年前,在最强的计算机也不见得可以玩赛车游戏;10年前,个人电脑已经可以玩画质还可以的3D赛车游戏了;现在,自动驾驶+5G云驾驶已经快成为现实。在这背后,是无数的硬件技术飞跃,以及吃掉了这些硬件的各类软件。这也是我们每隔两三年都要换手机的原因:不是机器老化变卡了,是嗜血的软件在作怪。

因此,即使现代的硬件水平已经强悍到如此境地,性能优化仍然是有必要的。软件日益复杂,抽象层级越来越高,就越需要底层基础设施被充分优化。对于大部分开发者而言,高层代码逐步走向低代码化、可视化,“一行代码”能产生的影响也越来越大,写出低效代码则会吃掉更多的硬件资源。