Http协议升级之路
几乎所有Web相关的技术都离不开其传输协议HTTP, 纵观HTTP本身的发展历程, 从简单到复杂, 再到一个完备的体系, HTTP在不断完善的期间如何解决各种问题的方式, 非常值得学习
HTTP 0.9 HTTP 1.0
HTTP建立之初, 主要就是为了将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器. 但随着技术的发展, HTTP所做的事情已经远远不止于传输html这样简单, HTTP基于TCP协议, TCP建立连接的3次握手和断开连接的4次挥手以及每次建立连接带来的RTT延迟时间逐渐成为了用户体验和服务器性能的绊脚石.基于HTTP的特性, 能够优化的主要在这三个方面, 后面HTTP的发展和优化主要也是从这些方面着手的, 尽可能多的同时加载资源, 尽可能少的重建TCP连接.
- DNS查询: 发送请求的域名需要通过DNS解析,缓存DNS信息能够减少查询DNS服务器的时间
- 浏览器阻塞: 对于同一个域名, 浏览器一般都有限制策略, 同时请求的资源过多时, 后续请求会阻塞排队等候
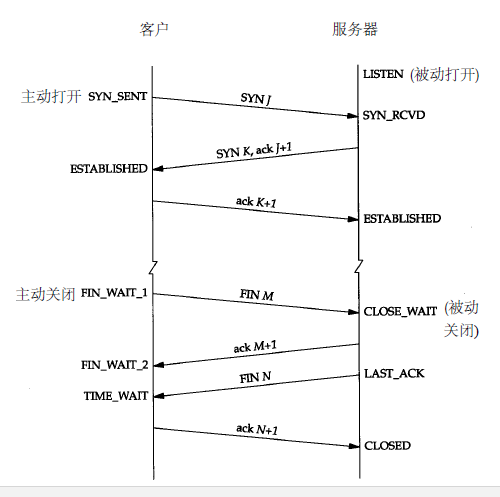
- TCP连接: HTTP1.0的TCP连接是不能复用的, 每次请求都会建立连接, 关于TCP连接的基础知识见下图

HTTP 1.1
HTTP1.1在1999年才开始广泛应用于现在的各大浏览器网络请求中,同时HTTP1.1也是当前使用最为广泛的HTTP协议. 它与HTTP1.0的主要区别主要体现在下面几点.
- 缓存处理, 在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准, HTTP1.1则引入了更多的缓存控制策略例如Entity tag机制, If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略.
- 带宽优化及网络连接的使用, HTTP1.0中, 存在一些浪费带宽的现象, 例如客户端只是需要某个对象的一部分, 而服务器却将整个对象送过来了, 并且不支持断点续传功能, HTTP1.1则在请求头引入了range头域, 它允许只请求资源的某个部分, 即返回码是206(Partial Content), 这样就方便了开发者自由的选择以便于充分利用带宽和连接.
- 错误通知的管理, 在HTTP1.1中新增了24个错误状态响应码, 如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除.
- Host头处理, 在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址, 因此, 请求消息中的URL并没有传递主机名(hostname).但随着虚拟主机技术的发展, 在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers), 并且它们共享一个IP地址.HTTP1.1的请求消息和响应消息都应支持Host头域, 且请求消息中如果没有Host头域会报告一个错误(400 Bad Request).
- 长连接, HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理, 在一个TCP连接上可以传送多个HTTP请求和响应, 减少了建立和关闭连接的消耗和延迟, 在HTTP1.1中默认开启Connection: keep-alive, 一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点.
但是HTTP1.1仍然存在一些问题, 比如明文传输, 每次都会传输一个相对较大的头, 长连接带来的服务端压力等等, 针对HTTP安全性的问题, HTTPS出现了.
HTTPS
HTTP协议运行在TCP之上, 所有传输的内容都是明文, HTTPS运行在SSL/TLS之上, SSL/TLS运行在TCP之上, 所有传输的内容都经过加密的. 这里有一篇关于SSL/TLS协议的深入分析, 看完之后感觉自己对HTTPS的理解太皮毛了, 这里概括的划下重点.
TLS大致是由3个组件拼成的:
- 对称加密传输组件,例如aes-128-gcm
- 认证密钥协商组件,例如rsa-ecdhe
- 密钥扩展组件,例如TLS-PRF-sha256
组件可以再拆分为5类算法,在TLS中,这5类算法组合在一起,称为一个CipherSuite:
- authentication (认证算法)
- encryption (加密算法 )
- message authentication code (消息认证码算法 简称MAC)
- key exchange (密钥交换算法)
- key derivation function (密钥衍生算法)
TLS设计了一个算法协商过程,来允许加入新的算法
例如下面这样一行CipherSuite意义是 :
ECHDE密钥交换, RSA做认证, AES-128-gcm做对称加密 其中由于GCM属于AEAD加密模式, 无需单独使用Mac算法
ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2 Kx=ECDH Au=RSA Enc=AESGCM(128) Mac=AEAD认证密钥协商与对称加密传输构成了TLS的通信协议层, 而大部分对SSL/TLS的文章中多是认证密钥协商的阐述, 而对称加密传输过程很少涉及, 经过一些浅显的了解, 我发现其实对称加密传输时, 远远不止是用交换的密钥和一个对称加密算法(AES, RC4[这家伙已经被破解不能用了])加密解密这样简单, 这个过程需要分片/重组、压缩(有漏洞的)、加密解密、HMAC(Hash-based Message Authentication Code)验证. 不同的加密模式差别很大, 以GCM为例, GCM模式是AEAD(关联数据的认证加密)一种, 是一种Encrypt-then-MAC模式, 关于密码模式的分类这里有详细解释wiki 这些加密模式需要用到一个很重要的参数即初始化向量IV, 必须用密码学安全的伪随机数生成器(CSPRNG)生成, 另外, 现在主流的AEAD模式不需要MAC key, 需要一个增长序列(nonce)参数, 这些参数通过组合散列等方式扩展密钥, 用于加密传输. 在TLS1.3中, 密钥扩展使用HKDF算法, 更加安全.
而认证密钥协商的过程就是握手建立连接的过程, TLS1.2与TLS1.3差别比较大, 但主要思路就是通过非对称加密算法, 来实现客户端和服务端的身份确认(数字证书), 并交换一个用于此次会话的基础密钥. 基于大数分解的RSA算法和基于椭圆曲线的DH算法,不断发展为3类非对称算法:
- 非对称加密 RSAES-PKCS1-v1_5,RSAES-OAEP, Rabin-Williams-OAEP, Rabin-Williams-PKCS1-v1_5 等
- 非对称密钥协商 DH,DHE,ECDH,ECDHE 等
- 非对称数字签名:RSASSA-PKCS1-v1_5,RSASSA-PSS, ECDSA, DSA, ED25519 等
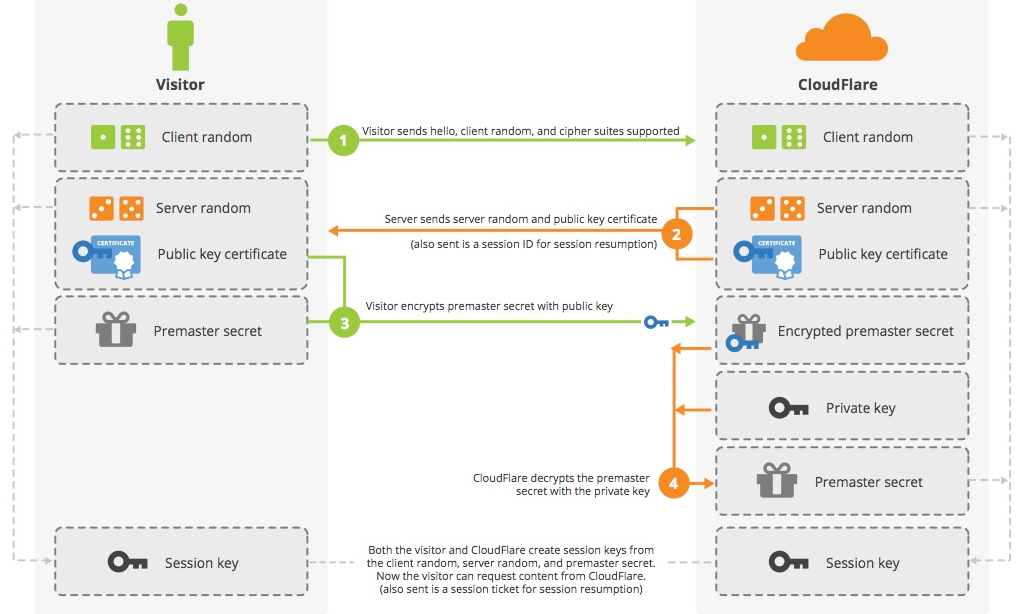
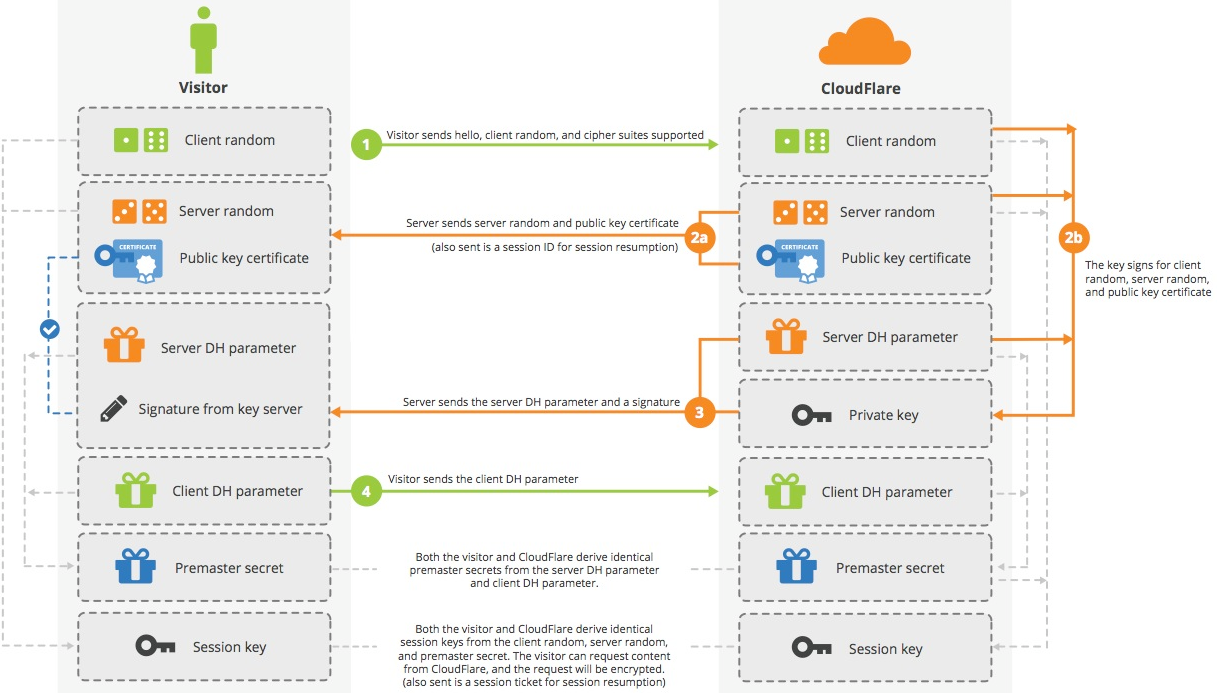
现在主流的做法是使用RSA算法做身份认证, DH算法做密钥交换, DH在交换密钥时, 客户端和服务端无需直接传送密钥, 而是根据DH参数各自计算出来真正的密钥, 比RSA更安全. 这里盗了几张图, 分别是RSA做密钥交换时的序列图(AES256-GCM-SHA256)和DH做密钥交换的序列图(ECDHE_ECDSA_WITH_AES_128_GCM_SHA256)
RSA算法做密钥交换 
 DH算法做密钥交换
DH算法做密钥交换 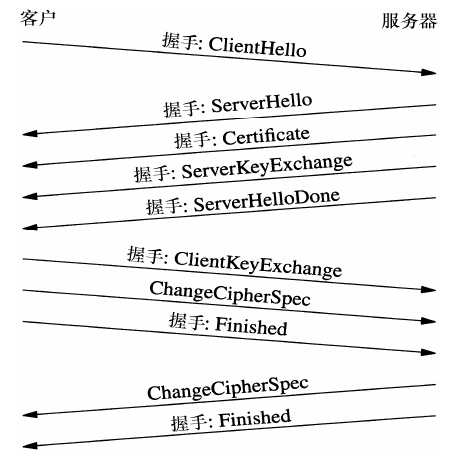
 TLS1.3目前已经逐渐普及, 例如github在客户端已经禁用TLS1.2, 导致低版本的git无法使用. TLS1.3重大的改动主要有:
TLS1.3目前已经逐渐普及, 例如github在客户端已经禁用TLS1.2, 导致低版本的git无法使用. TLS1.3重大的改动主要有:
- 0-RTT支持, 1-RTT握手支持 (TLS1.2是2-RTT的)
- 改为使用HKDF做密钥扩展
- 彻底禁止RC4
- 彻底禁止压缩
- 彻底禁止aead以外的其他算法
- 去除aead的显式IV
- 去除了AEAD的AD中的长度字段
- 去除ChangeCipherSpec
- 去除重协商
- 去除静态RSA和DH密钥协商
插曲 SSL Strip攻击
SSL剥离攻击是一种中间人劫持实现的降级攻击, 具体实现如下 如何进行一次完整的 SSLStrip 攻击
相对于各种TLS算法漏洞和算法降级攻击, 这种粗暴的HTTPS剥离为HTTP攻击算是比较简单的, 当然防御的办法也很简单, 就是HSTS HSTS的全称是HTTP Strict-Transport-Security, 它是一个Web安全策略机制, 用来强制进行Https通信, 表现在浏览器上就是一个响应头
Strict-Transport-Security: <max-age=>[; includeSubDomains][; preload]添加这个相应头, 就可以告诉浏览器,在接下来的xxx时间内,对于当前域名及其子域名的后续通信应该强制性的只使用HTTPS,直到超过有效期为止.
但HSTS存在一个比较薄弱的环节, 那就是浏览器没有当前网站的HSTS信息的时候, 或者第一次访问网站的时候, 依然需要一次明文的HTTP请求和重定向才能切换到HTTPS, 以及刷新HSTS信息。而就是这么一瞬间却给攻击者留下了可乘之机, 使得他们可以把这一次的HTTP请求劫持下来, 继续中间人攻击.
解决这个隐患的办法就是Preload List
浏览器里内置一个列表, 只要是在这个列表里的域名, 无论何时、何种情况, 浏览器都只使用HTTPS发起连接.这个列表由Google Chromium维护, FireFox、Safari、IE等主流浏览器均在使用. 有一个正确的证书和Https站点, 就能将域名申请到这个列表中, 申请地址在这里
HTTP2.0
2012年Google提出了SPDY的方案, 采用带优先级的多路复用、Header压缩、服务端推送等多种技术手段, 大幅度提升了页面加载速度, 但之后大部分浏览器只支持HTTPS协议之上的SPDY协议, 实际上对HTTP协议并没有兼容, 后来HTTP2.0出现了, 在SPDY的思路上又做了一些改进, 并兼容HTTP协议. 这里列举了几个HTTP2.0的特性, 大部分是与SPDY类似的
- 二进制分帧层 HTTP1.x基于文本, 2.0使用二进制格式, 最小单位为帧, 能够交错并行发送请求和响应, 解决了HTTP1.x的阻塞问题, HTTP2.0中, 超过2的14次方-1(16383)字节的数据就会分帧发送
- 多路复用 由于引入了一个二进制分帧/重组层, 自然而然的实现了多路复用, 每个请求有一个ID, 并附带优先级, 这样缓解了HTTP1.x为了提高性能建立多个TCP长连接带来的服务端压力
- Header压缩 HTTP2.0使用了HPACK算法减少HTTP头的大小, 相比SPDY采用的DEFLATE压缩算法更加符合HTTP协议的应用场景
- 服务端推送 当请求一个资源时, 服务器会顺便把关联的资源一并发送过来, 当浏览器需要使用时会发现一切尽在缓存中, 得来全不费工夫啊, 这里是一个Nginx实现推送资源的配置例子, nodejs中也有SPDY模块用来创建一个HTTP2/SPDY服务器.
HTTP3.0
HTTP2.0已经有很多优化了,但遇到了新的瓶颈,高速可靠网络中TCP的优势反而成了劣势:
- TCP的有序性,单个TCP长连接会有排头阻塞问题
- TCP的可靠性,接收方需要不断发送ACK才能让滑动窗口继续滑下去
- TCP拥塞控制机制,慢启动和拥塞避免等等传统TCP拥塞算法,导致不能高效利用带宽
HTTP3.0目前还没有正式发布, 一个简单的理解可以是 HTTP3.0 = HTTP2.0 + QUIC
QUIC是何许人也?全称Quick UDP Internet Connection,递归写法就是QUIC了,是Google发起的一种基于UDP的可靠传输协议,因为UDP不可靠(不仅有协议本身的问题,另外UDP的无连接性导致NAT设备无法确认连接关闭状态,ISP丢包等等问题),Google的天才们想了很多办法让UDP可靠了,搭配HTTP2.0就是目前所说的HTTP3.0草案。目前HTTP3.0用的极少,这里不再展开。这里也有一篇关于HTTP发展到3.0的文章,Mark一下:https://mp.weixin.qq.com/s/fC10Cyj6xjjwOCnqxX-Dvg