软件设计杂谈——可伸缩性
引言
当后端服务并发高到一定程度时非常考验软件架构设计,除了尽可能提升单机性能外,拥有强大的可伸缩性(Scalability)至关重要。如何提升软件系统的Scalability呢?
最简单的思路是水平扩展:1个撑不住就来10个,10个撑不住就来100个,100个不行就1000个。
这个思路看似没什么问题,然而真正实现起来却很难,我们再深入探究下去。
从有状态组件的剥离谈起
水平扩展的难点在于有状态的服务是很难水平扩展的,而整个系统的瓶颈往往会出现在有状态的组件上,比如数据库和缓存服务。
因此对于整个后端分布式系统,要实现水平扩展能力,首先要把有状态的组件拆分出来或者添加代理原入口的路由层,这样水平扩展出来的N个实例之间才具有可替代性。
以典型的状态数据:登录Session为例。如果把Session简单存储在服务端内存中,连水平扩展成两个实例都做不到,可以用下面这几个办法来解决:
- 把Session从内存移到Redis缓存中,可以让服务端自身变成无状态的,但Session这个“状态”其实转移到Redis中了,如果并发高到一定程度还是要解决Redis的瓶颈;
- 把Session干掉,客户端登录后换取无状态但有过期时间的令牌,令牌拿到任何一个实例中都可以验证,常见的实现有JWT,确切的说是JWT中的JSON Web Signature (JWS);
- 如果采用了方法1,要缓解Redis可能的瓶颈,更进一步的办法是对用户的Session数据进行人为或自动的拆分,或者说分片(Sharding),比如下面两种做法:
- 人为拆分数据:找某个用户数据的属性来人为分片,以省份为例,不同省份的用户登录进入不同省的服务器,这样并发就少了一个数量级。但是这又带来了新的问题,跨省查询就麻烦了,而且有的省人多有的省人少,存在资源利用不均的负载均衡问题;
- 自动拆分数据:可以用Redis Cluster,而不是用传统的主从加哨兵模式,Redis Cluster总共16384个Key的槽位,会分配到N组Redis Master中,存取数据时根据Key的CRC16值自动计算所落槽位,以此判断谁来处理客户端请求。这样一方面对数据做了分片,另一方面更多的Redis实例能支撑更多的客户端连接。如果新增或去除一组Redis Master/Slave,通过简单的运维操作,可以自动进行槽位的重新分配和数据迁移,这种动态的拆分数据的方法比上面人工的Sharding看上去更好一些,但仍然可能存在热点Key问题。总的来说瓶颈进一步被缓解了,能够支持服务端进一步水平扩展。
通过这个实际例子,可以发现仅仅是Session这样一个看似简单的问题,还没有涉及更难解决的瓶颈(比如实时通信层的有状态连接管理,存储层的分布式数据库等等),就足以掣肘整个系统的可伸缩性。
可伸缩性的三个维度
回到理论层面,如何才能做到近乎无穷的伸缩性呢?下面这张“Scale Cube”来自Marty Abbott的《The Art of Scalability》
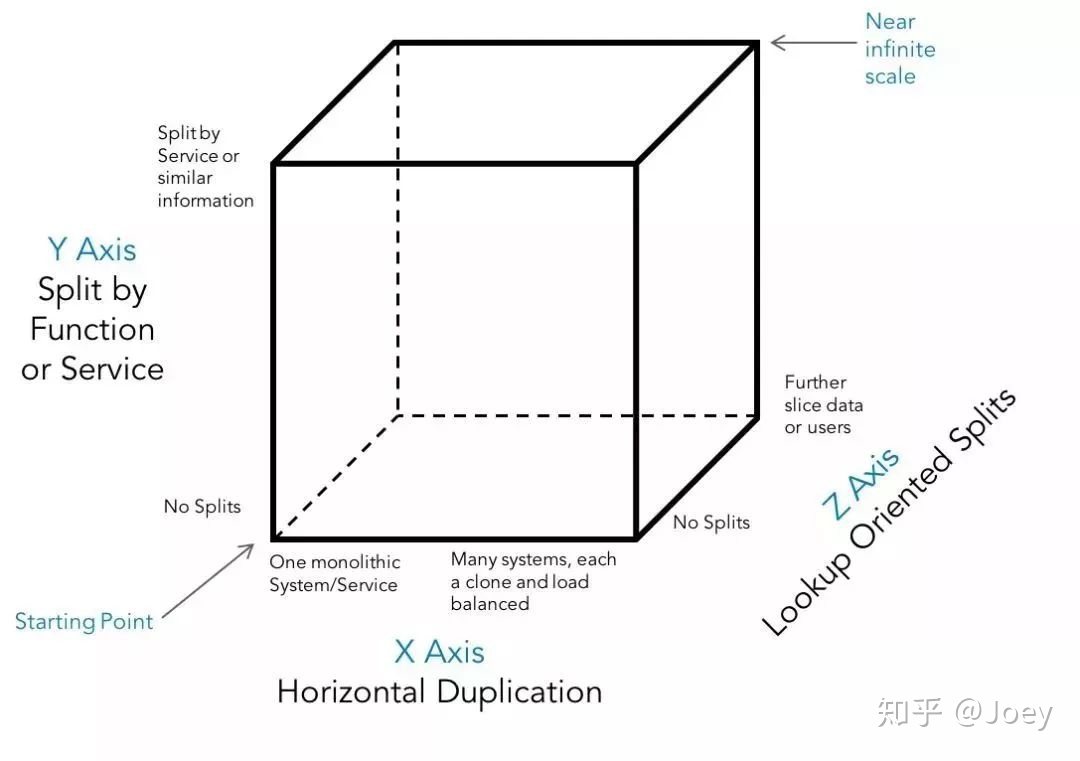
图中有三个正交的维度,需要对每个维度都施以对应的方案,才能做到整个系统的可伸缩。
- X轴,把1个实例变成N个实例,也就是最初的思路,无状态服务可以依靠基础设施平台的能力实现理论上无限的扩容,再加上负载均衡层来分配每个实例干的活;
- Y轴,把单体系统变成N个子系统,需要构建领域模型,解构分割出耦合相对较小的多个服务,再以此将单体业务系统拆分落地成微服务系统;
- Z轴,把整体数据变成N块数据,用数据分区分片的技术拆分数据,或者部署N个独立完整的系统处理不同区域的业务,来缓解“有状态数据”剧增的瓶颈。
总结
可伸缩性的三个维度,X,Y,Z 每个轴做好的难度都是上不封顶,下面这张图是AWS和Netflix多年前通过链路追踪画出来的微服务依赖图。

这样怪物一般复杂系统的形成,也源自同样的思维方式和理论。曾见过阿里的监控平台画出来的链路图,比Amazon有过之而无不及,这么大体量高并发的复杂系统,对X轴在基础设施平台的要求,Y轴在架构设计的要求,Z轴在分布式中间件和存储组件的要求都是极高的,在这些方向上做到极致的人和团队是非常值得敬佩的。