软件设计杂谈——云原生12要素
"Twelve-Factor App"的概念出现很久了,一般叫"12要素",用来衡量一个后端服务是否适合搬到云上。以前不太明白其中的含义,经过一些实战之后,再回头看这些理论,发现这些“要素”个个一针见血,讲的正是实践中最容易踩的、最常见的坑。
12要素具体指什么?
"Twelve-Factor App"是Heroku创始人Adam Wiggins在2012年提出的(https://12factor.net/),描述云端服务应当遵循的一些最佳实践。相比于不符合这些特征的传统应用服务,具有这些特征更合适云化。“Twelve-Factor”指的是下面的12条(不是一一对应翻译):
- Codebase:基线代码
- Dependencies:显式和隔离的依赖
- Configuration:配置分离存储到环境中
- Backing services:分离基础的后端组件
- Build, release, run:严格分离构建、发布、运行
- Processes:无状态的服务进程
- Port binding:自带端口绑定
- Concurrency:通过进程的水平扩展增大并发能力
- Disposability:易处置 - 快速启动和优雅退出
- Dev/prod parity:环境对等
- Log:日志作为事件流
- Admin processes:分离管理类任务
如何理解这12点?
Adam是在Heroku这个Platform as a Service模式的企业积累了大量经验,总结出的这些“要素”。对于PaaS提供商,关注的是应用服务如何在其Platform上运行的更好,因此要理解这些要素,我们先得搞清楚一个服务是怎么在Platform上跑起来的,简化的流程如下图所示:
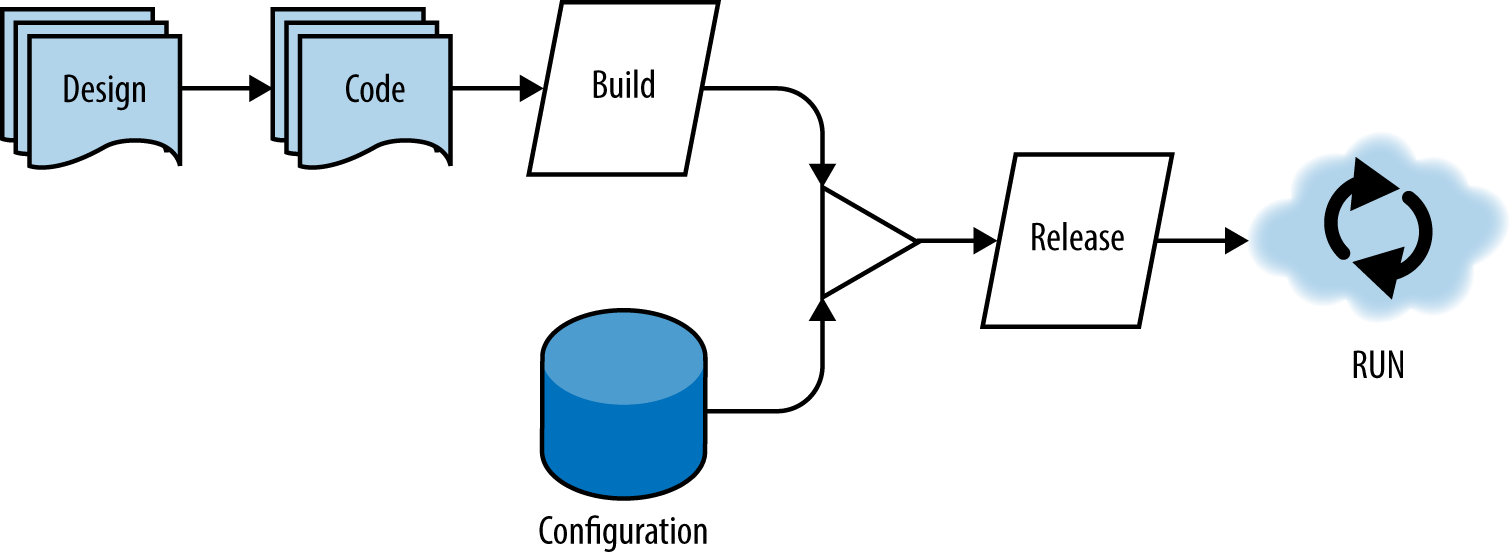
注:图片来自《Beyond the Twelve-Factor App》
落实到真实场景中具体是什么样的呢?Heroku国内用的很少,我们以标准的Kubernetes平台为例展开来看:一个典型的容器化的后端服务,从开发到上线需要经历哪些步骤。
- 设计阶段:需求分析和领域设计、技术选型确定依赖的框架和组件、建立项目框架
- 开发阶段:开发、测试、代码评审,迭代到可发布的版本
- 创建镜像仓库,为服务编写Dockerfile,构建出服务的容器镜像
- 创建容器编排文件,确定非产线环境部署运维阶段的各项细节
- 在测试环境确认基础设施容量以及第三方组件,符合条件并初始化完毕,比如数据库的创建和初始化DDL的执行
- 准备部署到测试环境,在配置中心创建或更新配置文件,配置参数和密钥等
- 创建或更新持续集成、交付系统的任务管道, 执行CI/CD Pipeline,部署到测试环境
- 配置测试环境的访问入口,如反向代理的路由、域名等等
- 日志、监控、告警、链路追踪等相关组件接入
- 在测试环境进行完整的功能集成测试、性能测试
- 在预上线环境,重复步骤6-10
- 在产线环境,重复步骤6-10
- 继续迭代,完成开发和单测后,在每个环境重复步骤6-10,其中7,8,9中无需修改的部分可以跳过
- 每次迭代灰度发布,逐步放开新版本的流量
可以看出,一个正经的后端系统,初次上线和后续迭代的流程已经比较复杂。如果单靠人力,单体系统勉强可以应付,毕竟单体系统即使变成"大泥球",也大多处于人力可控的范围内。但随着复杂度进一步提升,整个系统演化成微服务系统,往往包含十几个、数十个、甚至成百上千个子服务,多个服务之间还有依赖关系,这其中的技术挑战是显而易见的。
复杂性无法避免,如何在复杂情况下,尽量提高效率、减少错误呢?
答案就是,在设计和开发阶段去迎合云平台以及整个生态的能力,从一开始就要做一个适合在云上跑的服务。
“12要素”应运而生,给了我们一把衡量“是否适合上云”的标尺。用个不太恰当的说法就是“屁股决定脑袋”。如果不遵循这些“要素”,不适应云平台提供的能力、不剥离业务无关的部分,随着服务规模增大、业务复杂度进一步提高,就非常容易引发问题了。
这也是“12要素”出现的背景和原因,了解这些之后,其内容就更好理解了。下面我们把12要素归为两类,一类是放之四海而皆准的,第二类是对云原生应用特别重要的,以举反例的形式逐一讲解。
第一类:几乎任何场景都适合的
基线代码 - Codebase
One codebase tracked in revision control, many deploys.
基线代码可以理解为多层意思:一个项目一个仓库;Git分支也不要分岔之后合不回来了;不要在多个仓库出现重复的代码,把通用的代码抽成独立维护的仓库。
反模式的例子:多个不相干项目数百万行代码全部放到一个代码仓库;对于一些需求差异,直接复制项目仓库单独开发,同时维护多个仓库代码。想象一下这两个例子,CI/CD系统心理阴影面积多大。
另外,代码仓库的管理还影射了更深的含义。康威定律告诉我们,组织和团队的形态最终会反映到产品的形态上。因此看一个公司的代码仓库如何被创建和管理的,这个公司开发团队组织结构和技术管理水平也可见一斑。
显式和隔离的依赖 - Dependencies
Explicitly declare and isolate dependencies
完善的依赖管理机制、显式的依赖声明文件和版本锁机制,能够减少因为错误的依赖版本导致的Bug。
反模式的例子:Node.js之父Ryan Dahl另起炉灶创造了Deno,Deno的import远程代码就是Node世界的npm反向极端,造成了隐式依赖;Golang在1.13之前没有go module的时候,也是违反这条原则的。且不说不清晰的第三方依赖容易导致“投毒”,这对代码的问题定位、维护、交接都是很大的负担。
注:这一小节的“反模式”并不是指技术本身哪里不好,其创造者都是世界顶级的工程师和科学家,仅指它们的一些原生特性,对开发复杂的应用不够友好。
配置分离存储到环境中 - Configuration
Store config in the environment
配置数据和构建产物完全分离,配置数据单独管理,只在运行环境中出现。
《Beyond the Twelve-Factor App》中有一个比喻:代码制品、生产环境配置 是两个危险的化学物质,混合到一起就可能随时爆炸。因此,我们需要把配置(尤其是密钥类、功能开关、策略类配置)的重要性提升到很高的级别,小心翼翼地管理。
若是配置不完全和代码分离,相当于两个危险的化合物一开始就被混合在一起,部署的时候原地爆炸也不足为奇。
反模式的例子:环境相关的配置,混在容器镜像、甚至代码包中,每个环境需要单独构建打包一个版本。这种“不正确”的做法在传统的开发模式中很常见。
分离构建、发布、运行 - Build, Release, Run
Strictly separate build and run stages
在本节一开始分享的图中有6个阶段:设计、开发、构建、发布、配置、运行。
配置在上一小节已经说明为什么一定要分离出来。设计、开发在传统软件生命周期模型中已经是两步。
剩下的3个阶段就是:构建、发布、运行,而这三者在传统软件的发布流程中通常并没有完全分离。
为什么要强调“构建、发布、运行”三个阶段一定要分离开来呢?
有两个好处:
- 职责和关注点的分离。构建是开发测试人员更关注的、发布是产品经理更关注的、运行是运维更关注的;
- 流水线模式带来的效率提升,以及各阶段之间的缓冲空间,每个阶段有专门的工具和方法论。
怎么做到这三个阶段的分离呢?流水线的运行不是靠人力保障的,自动化系统很重要。用好CI/CD系统、项目管理系统,制定好规则和流程并自动运转起来,足矣。
反模式的例子:开发改完代码,本地打个Patch发给运维,也不告知产品经理改了什么,直接口头告诉运维批量更换某些文件。
环境对等 - Dev/prod parity
Keep development, staging, and production as similar as possible
开发、测试、预上线、生产环境等等,甚至本地环境,都保持环境一致,这样能最大限度减少“我本地是正常的啊”、“开发环境是正常的啊”、“是不是环境/机器问题”这类甩锅式的抱怨。
反模式的例子:开发环境不容器化,产线容器化;开发环境用的MariaDB,产线用的MySQL;开发环境数据库没主从,产线配置了主从同步。MySQL读写分离时,主从同步那几毫秒的延迟导致各种奇怪Bug,在开发环境也许永远都重现不出来。
第二类:对云原生应用及其重要的
这篇题目为什么叫“云原生12要素"呢?其实Adam的原义只是说云端应用应当具备的特征,并不是指云原生(Cloud Native)。本文想讲的不单是跑在云端的应用,而是有更现代化特征的云原生应用,所以用了这个题目。
其实在Adam提出“12要素”一年后的2013年,才出现“云原生”的概念,云原生的含义也经历了一些演变。
2015年Matt Stine在《Migrating to Cloud-Native Application Architectures》一书中对云原生的定义就是:
- 符合12要素(The Twelve-Factor App)
- 微服务(Microservices)
- 自助式敏捷基础设施(Self-Service Agile Infrastructure)
- 基于API协作(API-based Collaboration)
- 健壮、抗压能力(Anti-Fragility)
后来云2015年Linux基金会发起原生基金组织(CNCF),给出的定义是:容器、自动化、微服务。
到了2017年,Pivotal稍微改了一点,变成了:DevOps、持续交付、微服务、容器。
目前为止,CNCF官方最新的定义在技术上的概括是:容器、服务网格、微服务、不可变基础设施和声明式API。
云原生含义的演化过程,有一个基调一直没变,就是微服务。微服务是当前云原生应用的表现形式,或许云原生以后还会进一步增加Serverless。下面这些“要素”,对微服务/无服务的设计和开发非常重要。
分离基础的后端组件 - Backing services
Treat backing services as attached resources
所有依赖的基础组件或者其他应用服务,比如数据库、缓存服务、消息队列、二方/三方服务,都视为独立于自身之外的资源,独立部署,通过网络访问。
用面向对象的术语类比,就是视别的服务为“关联”的而非“组合的”。“关联”意味着更弱的耦合,仅通过网络端口与这些依赖的服务交互,而不是进程间通信。
“关联”模式像人与手机的关系,“组合”模式像人与人的大脑、四肢的关系。因此,“关联”模式还有一个好处,它会强迫我们去思考:如果依赖的服务宕机了怎么办?
就像很多人会有备用手机一样,大量的容错、降级处理的逻辑被写出来了,应用服务也获得了更强的鲁棒性。
反模式的例子:把缓存服务和应用服务打包到同一个容器镜像,通过/var/redis.sock这样的Domain Socket形式访问;或者把第二方应用服务的源码直接复制到自己的代码中,在一个进程中互相调用。
无状态的服务进程 - Processes
Execute the app as one or more stateless processes
按照上一节说的,把依赖的服务分离出去,一些应用服务已经可以实现“无状态”了。但有时候,还需要对应用内部做一些改造才能实现无状态。无状态是水平扩展的前提,对于Serverless应用更是必要条件。
反模式的例子:应用服务的多个实例之间互相通信,共享一些内存数据;或者开发自治的集群选主、任务分发等功能。
自带端口绑定 - Port Binding
Export services via port binding
不要依赖运行平台提供端口绑定的功能,提供出去的可运行程序,直接运行就会绑定到某个端口。比如Springboot应用通常内嵌tomcat/undertow/jetty等Java Web容器,构建出的包直接运行就绑定了端口。
反模式的例子:提供出去部署的包的是 放到Tomcat的war、放到IIS的dll,自己本身没有描述通信协议,也没有指定绑定的端口,完全依赖Tomcat/IIS的配置。
通过进程的水平扩展增大并发能力 - Concurrency
Scale out via the process model
无状态的应用服务,很容易实现水平扩展,自身不会制约到并发能力。传统应用服务通常是性能靠提升单机配置,可用性靠双机热备;而云原生应用,注重的是伸缩能力(Elastic, Scalable)。
反模式的例子:把Session放到内存中。
易处置:快速启动和优雅退出 - Disposability
Maximize robustness with fast startup and graceful shutdown
因为云原生应用需要保持更优秀的可伸缩性,服务的部署实例随时可能被创建出来、或者被销毁掉,这就要求服务自身提供快速启动和优雅退出能力。
不具有快速启动能力,水平扩容的速度受限;不具备优雅退出能力,缩容时未处理完的业务中断,会导致用户请求错误、数据不一致性等问题。
反模式的例子:很重的Java服务启动耗时十几分钟;缩容靠kill -9强杀进程;服务也没有实现收到SIGTERM信号进入“跛脚鸭状态”,也没有等待请求处理完再关闭进程。
日志作为事件流 - Logs
Treat logs as event streams
应用服务不应该管日志怎么处理,日志如何处理是平台的职责,而非应用自身的业务。因此,应用服务只要把日志作为事件流抛出去就好了,容器环境中,最好的办法就是直接打印到标准输出和标准错误(stdout, stderr)。
反模式的例子:项目中写了一堆log4xx的复杂配置,日志文件存哪个路径、多长时间轮滚、保留多久删除。传统的软件这是必备的,但云原生应用,请仅保留打印到标准输出/标准错误。还有一个反模式的例子,在应用内就通过代码把日志抛到Kafka这类Broker中,无形中也让应用服务和Kafka耦合到了一起。
很多人不相信日志打印到stdout/stderr就完事了,是因为不够了解云原生世界中,各类日志收集和处理组件的强大。我们对传统的做法习以为常,却忘记了“单一职责原则”。
分离管理类任务 - Admin Processes
Run admin/management tasks as one-off processes
什么是管理类任务(Admin Processes)?直译成“管理进程”感觉不太对,这里是Admin Processes指的是执行数据库DDL、周期执行的运维任务、一次性的数据迁移和修复等等这类事情,更贴切的说法是“后台管理任务”。
反模式的例子:在应用服务运行环境中安装一个数据库客户端,运维人员手动跑一堆修改数据库的SQL;或者安装一些运维脚本,放到机器的cron table定期执行一些脚本。
这一条“要素”看似晦涩难懂,看反例就很清楚了。例子中的做法是传统模式经常干的事情,但这种模式显然不“Scalable”,用自动化流水线和统一的任务调度平台,而不是手动SSH到机器上靠人做。《Beyond the Twelve-Factor App》中传达了更激进的观念:压根不要出现这类一次性的(“One-Off”)任务,这类业务也视为后端服务,调度中心仅触发一个HTTP/RPC请求,调用服务的接口做这类业务。
举个正例帮助理解:如果要实现每天跑一次的数据分析脚本,除了到机器上加crontab这个最坏的办法,还有什么其他办法呢?
《Twelve-Factor App》告诉我们,可以用一次性的容器,每天创建一个容器执行脚本,确认执行成功后随即销毁,不成功可以自动重试,比如Kuernetes提供的CronJob机制。
《Beyond the Twelve-Factor App》告诉我们,可以在应用内或单独做一个服务,提供一个HTTP接口做这件事,调度平台每天触发的是HTTP调用,根据调用返回结果决定重试。彻底去除Admin Processes,所有的东西都是可伸缩的Backing Service。
彩蛋:第三类
“12要素”是“云原生应用”的必要条件,但并不能构成充分条件。
Kevin Hoffman在2016年写的《Beyond the Twelve-Factor App》一书中,又重新修订了“12要素”,修改了一些描述,另外添加了API First、Telemetry、Authentication & Authorization三个要素。前两个对微服务系统非常重要,第三个则是安全性的核心保障机制。
- API First:以API为中心的协作模式,永远先定义好API再做其他事情。微服务系统的开发模式,大多是多个小团队齐头并进,设计好之后,先定义API就非常重要了。以API作为团队、应用服务之间沟通的桥梁。
- Telemetry:翻译成“遥测”有些别扭,属于可观测性(Observability)的一部分,上面说过的日志也属于可观测性的一部分。对于云原生系统,要杜绝传统的“SSH进去运行Debug工具”的事情发生,“遥测”是实现这一点的唯一手段。监控、告警、链路追踪,在微服务系统中缺一不可。
- Authentication & Authorization:认证和授权,属于安全性的要素,对传统的应用服务也适合。但云原生应用实现认证和授权的方式有所不同:对终端用户的认证授权往往在网关层就通过OAuth 2.0/OpenID Connect等协议统一处理了;对服务之间调用的认证授权通过Service Mesh可以做到零信任安全模式。
这三个Kevin Hoffman新增的“要素”,本文篇幅有限就不展开了,有兴趣可以读原著了解细节。
结语
本文简述了云原生应用应具备的12+3个特征,主要受到《Twelve-Factor App》和《Beyond the Twelve-Factor App》的启发,也借鉴了其中的一些理论和案例。写这篇文章,不是“3分钟入门云原生理论”,而是较长时间实战后,思考总结的一点浅薄的个人理解。
实践归纳出理论,理论指导实践。我们在真正开发一个应用服务时,尽量按这些指导思想,可以做的更加“Cloud Native”一些,但也不能教条主义,把这些视为“金科玉律”。日志一定要用stdout打印吗?Admin Processes一定要独立执行吗?所有的服务都能实现“无状态”吗?
都不一定。
Experience shows that compromise on purist ideals is as ever-present as death and taxes.
“取舍”、“折衷”、“Trade-off”,一直是工程领域的关键词。没有最好的,只有适合的。