为什么你可能不需要Nacos?
配置中心会有多复杂?
配置中心是微服务系统必不可少的组件之一,乍一看好像没多少技术含量,可是,真的是这样吗?
以Java Spring技术栈为例,主流的配置中心有阿里的Nacos、携程的Apollo、以及Spring Cloud Config Server。我们拆解一下其中共通的技术点:
服务端:
- 认证和权限控制:某个服务可以拿到哪些Key?人员的增删改查权限如何控制?
- 存储层的选型:文件系统,Git仓库,数据库?
- 安全性:传输加TLS,密钥需要落盘加密,本身用来加密密钥的密钥如何安全存储?
- 高可用、数据一致性:多实例部署,甚至跨区域同步,进而又带来分布式存储一致性问题,如何解决?
- 版本控制:修改记录需要保留,随时可能回退到历史版本,另外,灰度版本的配置隔离如何实现?
客户端:
- SDK如何兼容不同的技术栈?
- 大量客户端同时启动,如何做并发控制?同时还要尽可能减少额外的请求,对服务启动时间的负面影响?
- 如何实现与本地配置的优先级控制、合并、缓存、变化实时感知?
...
看到这里,或许你不会觉得配置中心只是简单的KV存储了。主流的型如Alibaba Nacos,作为一个完善的配置和服务发现组件,已经解决了上述大部分问题。我也曾用Nacos,Nacos非常棒,不过我也逐渐发现了一些局限性:
- 当你有数十个环境,每个环境有数百个配置的时候,基于图形界面的版本管理会力不从心;
- Nacos服务的网络、Server、数据库,任何一层出问题,都可能影响大量产线服务;
- 额外的学习、使用、部署、维护成本,服务启动的额外性能开销;
- 发生过一次产线事故,后来分析是因为Spring Cloud Nacos在刷新配置的时候,可能导致Bean Refresh死锁;
- 不支持新版本的SpringBoot/SpringCloud,在SpringBoot 2.3.0.M1之后直接报错(这个问题存在很久了,我在Github提了一个Pull Request修复该问题,多日没有收到答复 https://github.com/nacos-group/nacos-spring-boot-project/pull/189)
挥下奥卡姆剃刀吧,或许你不需要如此复杂的方案!
一行代码实现动态配置
我萌生了一个朴素的想法:既然配置原本就是单纯的文件,那么文件变化时,重新加载对应的Spring Bean不就行了吗?
于是,我开发了一个Spring Boot的配置热重载库,已发布到Maven中心仓库,Github开源仓库地址:https://github.com/Code2Life/spring-boot-dynamic-config。
话不多说,先看效果。
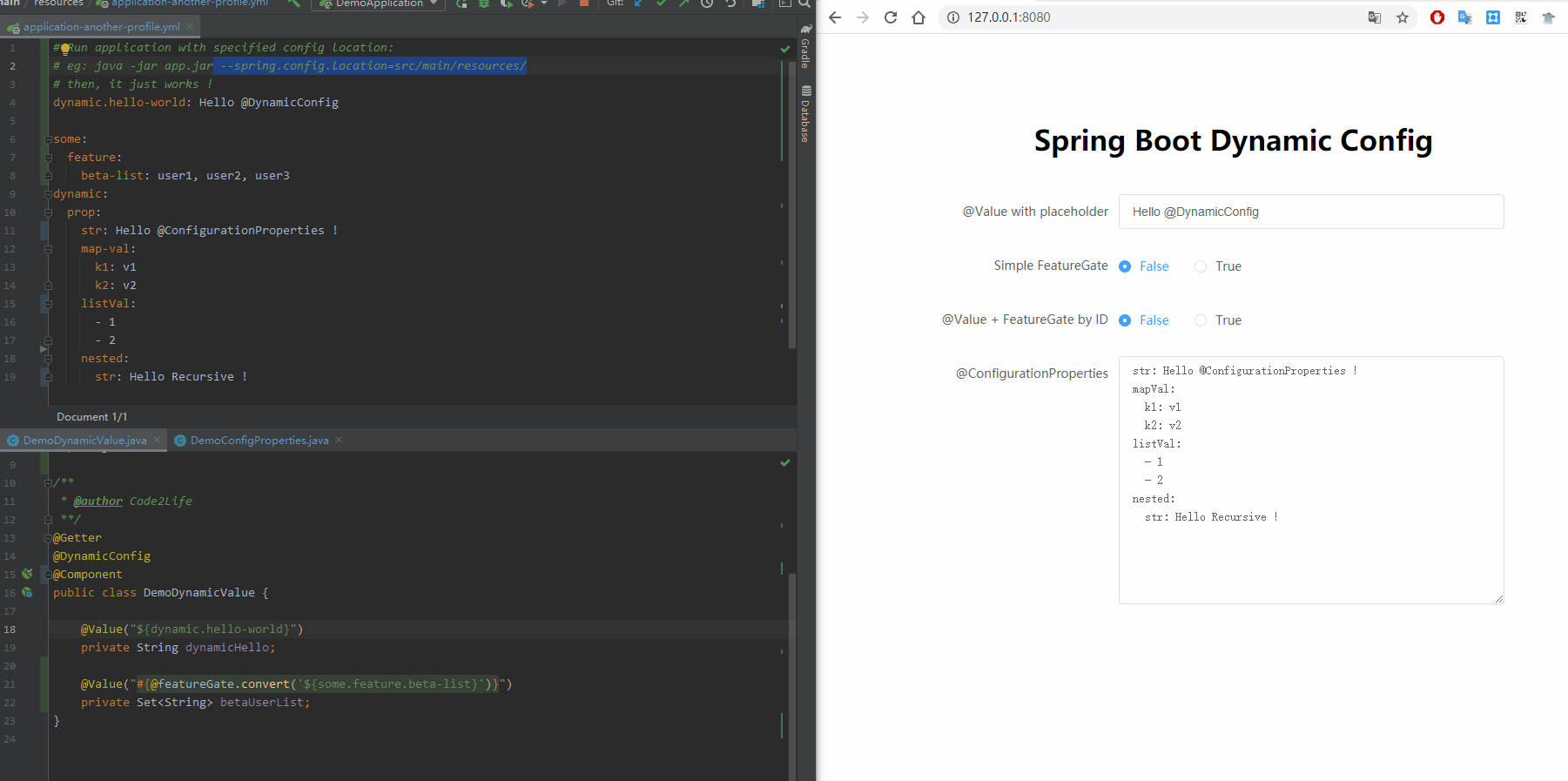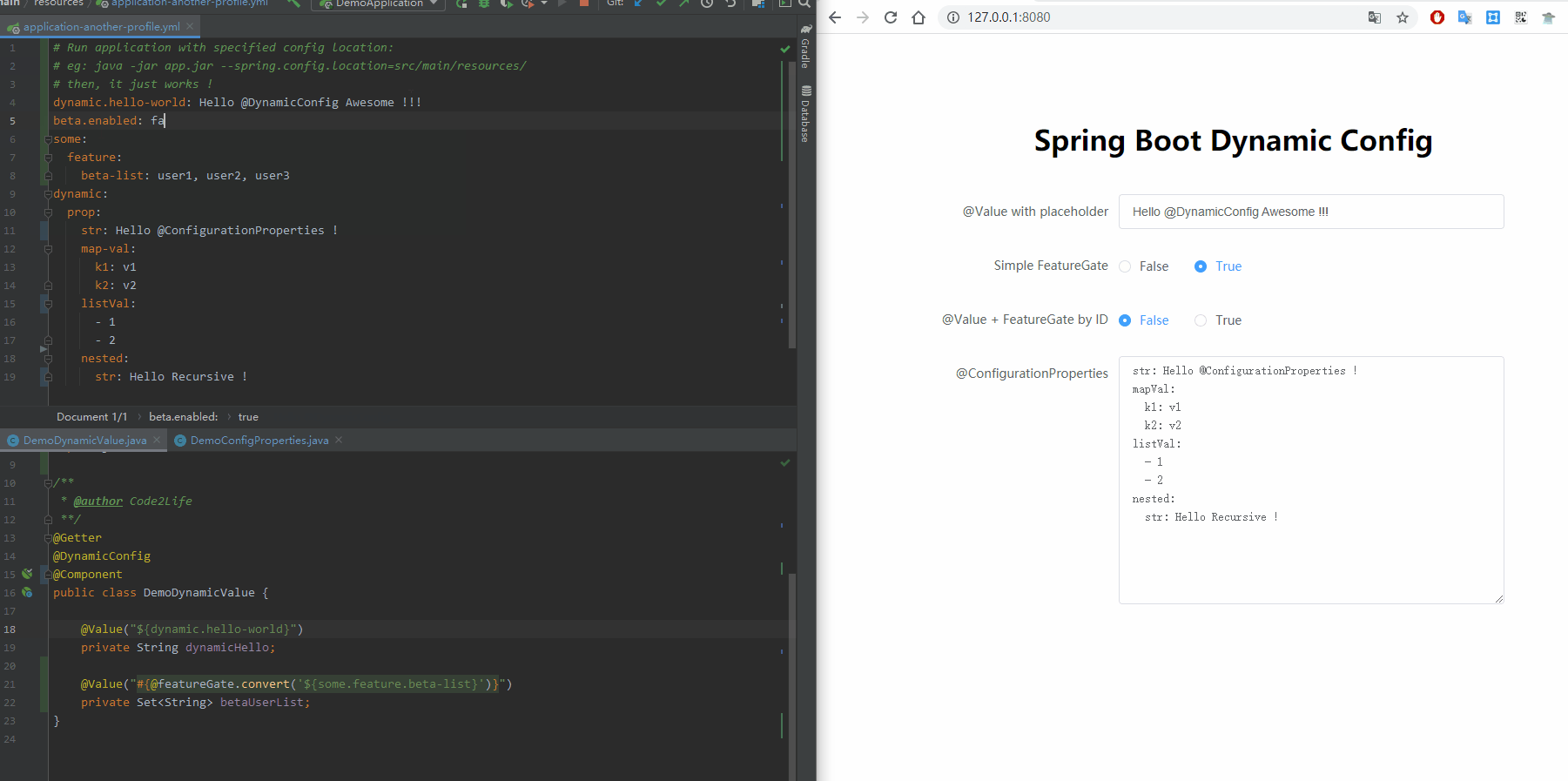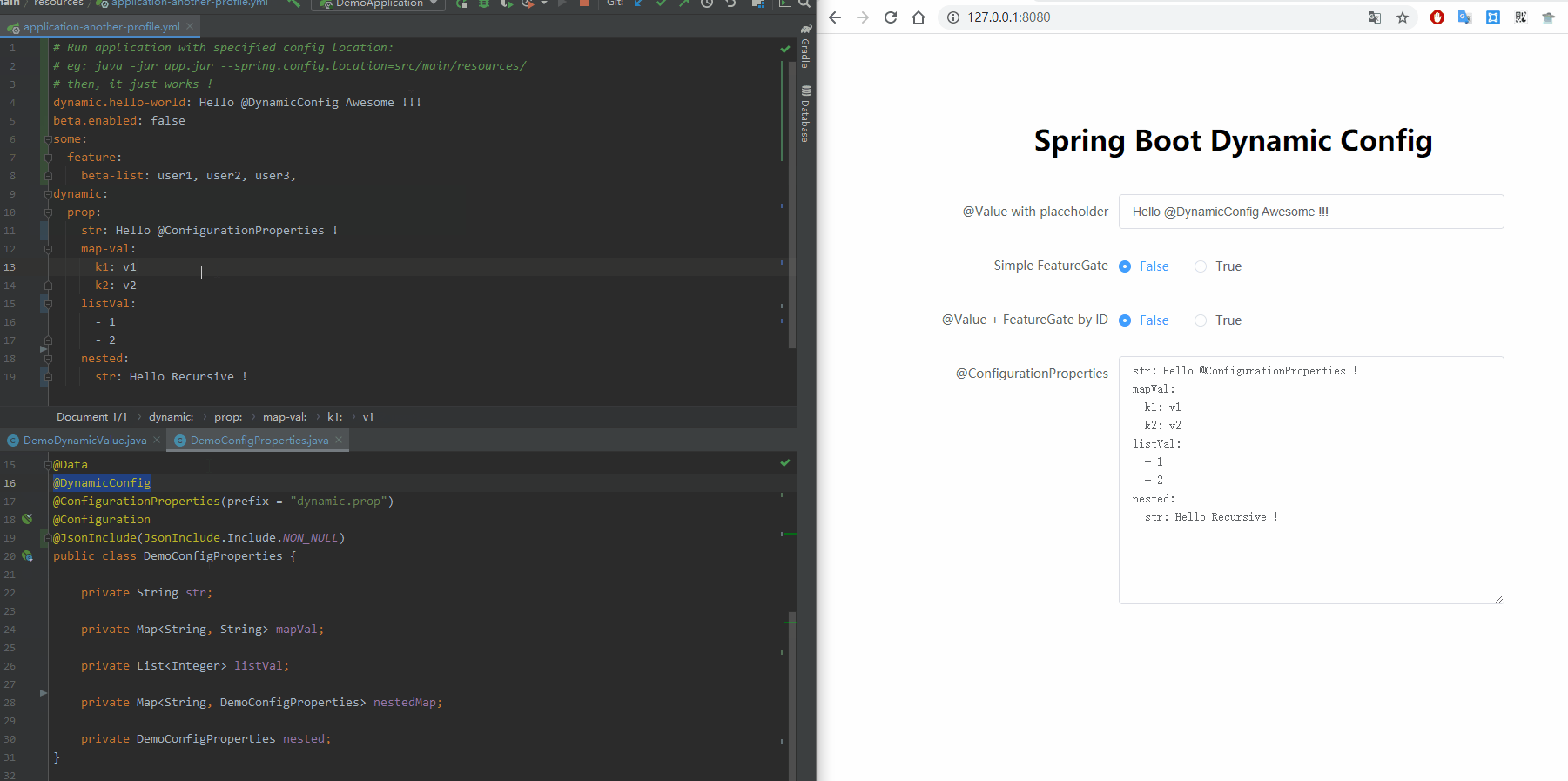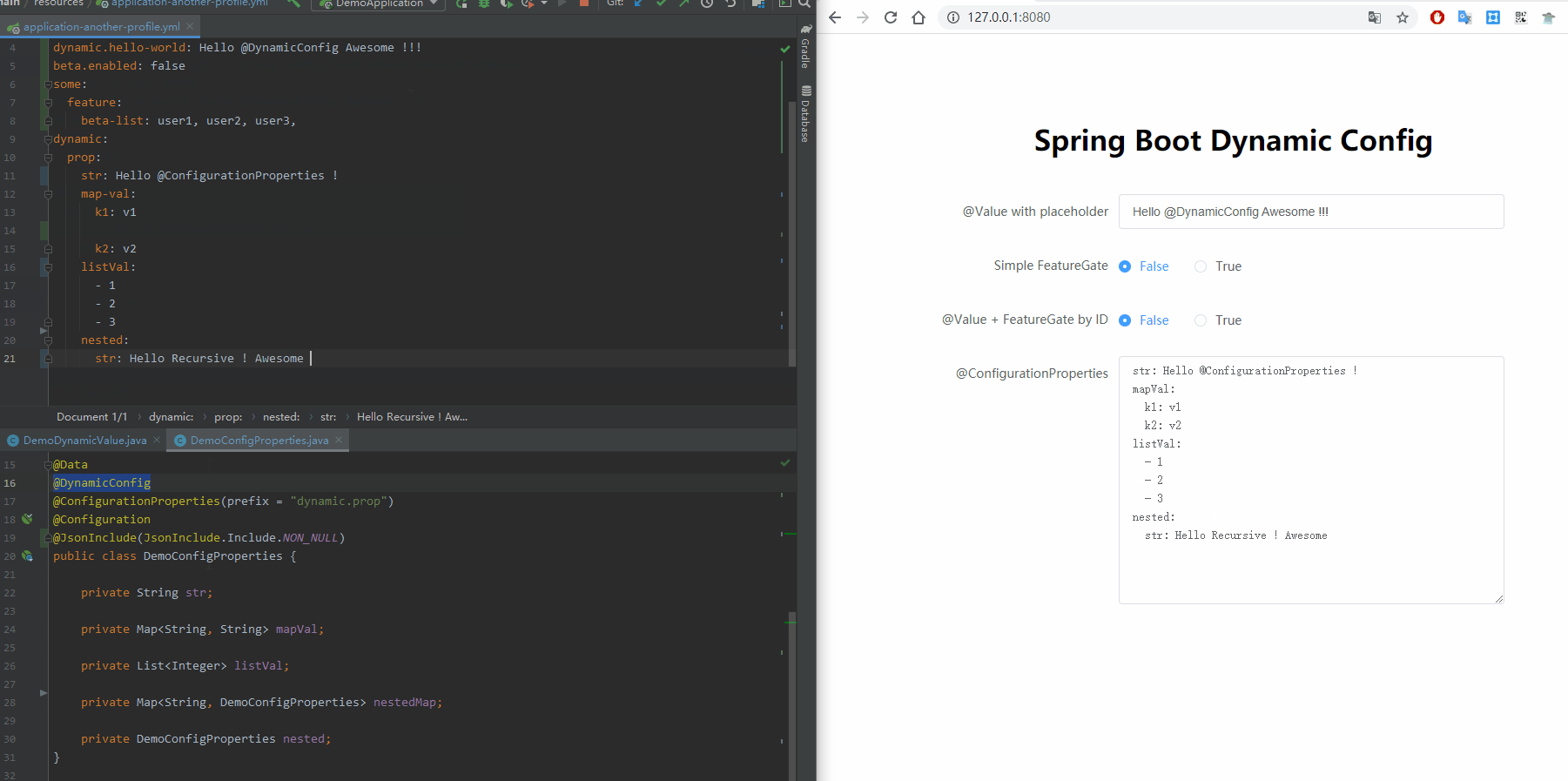
这个库的使用方式极其简单:只要在注有@Value/@ConfigurationProperties的类上,加上@DynamicConfig注解即可。
实现原理
我读了一些Nacos、Spring Boot、Spring Cloud的相关源码后,发现实现热重载配置有两类方案:
- 直接基于Spring/SpringBoot,通过自定义Bean的加载和PostProcessor机制开一个口子来实现;
- 二是基于Spring Cloud,本身就直接支持了动态配置。
我不想依赖Spring Cloud的任何组件,选择了实现难度更大的第一类方案,更难是因为单纯的Spring Boot没有Spring Cloud Starter的父Context和@RefreshScope注解,不能直接destroy原来的Bean,refresh一个新Bean出来,得“飞行中换引擎”。
文件变化监听
第一步,从Environment Bean的PropertySources里,把文件配置的PropertySource给揪出来。
// 需要先实现EnvironmentAware接口或自动装配StandardEnvironment
MutablePropertySources propertySources = environment.getPropertySources();
for (PropertySource<?> ps : propertySources) {
boolean isFilePropSource = isFromConfigFile(ps);
if (isFilePropSource) {
// 找到配置文件的PropertySource
}
}第二步,用Java NIO的Watch API监听配置目录。
watchService = FileSystems.getDefault().newWatchService();
Paths.get(configLocation).register(watchService, StandardWatchEventKinds.ENTRY_MODIFY, StandardWatchEventKinds.ENTRY_CREATE);
WatchKey key;
while ((key = watchService.take()) != null) {
for (WatchEvent<?> event : key.pollEvents()) {
reloadChangedFile(event)
}
key.reset();
}第三步,如果配置文件变了,把原来的PropertySource对象replace成重新创建出来的。
propertySources.replace(filePropertySourceName, newPropertySource);
// 上述代码只是一些示意片段,完整的实现参考在 DynamicConfigPropertiesWatcher 类至此,我们用数十行代码,已经实现了动态的Environment Bean,用getProperty()获得的结果已经是动态的了。
到此就结束了吗?
Spring Boot开发者一般是在Bean中使用@Value、@ConfigurationProperties来注入配置内容的,因此,原始的配置值已经分散IoC容器里各个相关的Bean中,我们还需要更进一步,在发生变化的同时,把这些Spring Context碗里相关的豆豆再揪出来,偷梁换柱。
修改Spring Bean的属性
- BeanPostProcessor切入Spring Bean加载流程,筛选出需要热重载Bean,完整代码在DynamicConfigBeanPostProcessor类。
- 接到配置变化通知时,开始移花接木,完整代码在ConfigurationChangedEventHandler类。
遇到的问题
因为要处理许多异常情况、兼容性问题等等,遇到了这两个问题:
- Linux软链接/Windows快捷方式文件,无法用JDK的WatchService监听。于是加了一个兜底策略:轮询文件的上次修改时间;
- @ConfigurationProperties类/嵌套类中如果有Map属性,Spring Boot的行为是做Merge Keys,而不是清空原有的Keys。我稍微改了一下,让最外层的Map变成清空策略;
- Spring Boot 从2.0到现在2.5,有一些核心类发生了变化,PropertySource的命名也有变化,做了一些兼容,而Spring Boot 1.x的版本差别太大无法兼容了。
在生产环境使用Spring Boot Dynamic Config
读到这里,或许你会质疑,这样做在本地开发没问题,但直接用文件的方式来管理开发/产线环境的配置,不是在开倒车吗?难道部署100个实例,要去100台机器上改配置文件?
当然不是。对配置文件的修改,一定,一定,一定要在Git仓库中,最好是独立于代码仓库之外的配置仓库。
为什么要用Git管理配置?
我参与了数十个Spring Cloud服务在全球十几个数据中心的容器化部署和运维,深刻体会了配置管理中的痛点。我们从相对简单的SpringCloud Config,换到功能复杂的Nacos,都没有解决掉本质的问题:应用配置是DevOps的一环,本应该和其他环节一样,通过GitOps的持续交付流水线实现自动化,不是去登录任何一个系统去输入任何一行配置。
我们设想一个场景,你作为一名开发,现在想更新一行产线配置。
Nacos的工作流是什么样的呢?
- 写一个部署文档或者发邮件告诉运维同事,要做一个什么样的修改;
- 运维同事收到邮件,找你开会确认;
- 上线期间,运维同事登录Nacos,找到对应的Namespace和DataID,点击“编辑”按钮;
- 你告诉运维要改的在哪一行,运维同事帮你修改好,点击“发布”按钮;
- 测完预上线环境,告诉运维同事没问题可以发布到产线了,运维再去手工操作上述步骤。
Git的工作流是怎么样的呢?
- 使用你喜欢的IDE打开你的应用配置仓库(这个仓库仅维护该应用服务的非敏感配置);
- 你改完后提交一个合并请求给领导/运维,同事确认无误点击合并,自动触发Pipeline实现配置上线,是哪个分支哪个环境就立即生效。
你不需要登录任何“配置管理系统”;你的运维同事不需要敲N下键盘、点N次鼠标;你不需要发邮件、写文档;甚至不需要和领导/运维同事发消息,整个过程就如丝般顺滑的在Git上完成了。
如果是开发环境,审批和走查流程灵活一些的话,配置Push到Git的开发分支,自动触发CI Pipeline,喝口水就生效了。
从这个场景可以看出,维护配置的职责交给Git,有很多好处。
- 维护期间,可以利用Git管理系统的权限机制,实现对谁可以提交,如何Review,谁可以合并到产线等等细粒度控制;
- Git本身具备完善的持续集成/持续交付(CI/CD)生态,通过触发CI/CD Pipeline,可以做到配置的秒级上线,跨区域同步上线;
- Git的版本控制能力极强,把配置文件从GUI系统放回到Git,是配置变得复杂之后的必然选择;
- 可以用你喜欢的任何编辑器或者IDE,甚至是Git管理系统自带的Web IDE都可以,语法检查也有了;
- 非常灵活,可以使用模板引擎生成配置,甚至自己开发DSL,这些都可以集成到CI/CD Pipeline中。
读到这里,或许你还有疑问:Git仓库里的配置内容,怎么就通过一个神奇的流水线,“变”到产线的那么多服务器的文件系统里面呢?还有在Git里面,肯定不能维护产线密钥,怎么办呢?
答案是Kubernetes。
Kubernetes的魔法
复杂的分布式系统,离不开基础平台的支持,Kubernetes就是这样一个业界标准级的云原生操作系统。
上一节说的神奇的流水线,并不是把文件拷贝到产线机器上,而仅仅是调用了一个HTTPS请求,来更新Kubernetes ConfigMap资源。
我们先回头看下一开始提的配置中心的技术难点,是怎么被Kubernetes ConfigMap/Secret功能完美解决的。
服务端:
- 认证和权限控制:Kubernetes天然的namespace隔离 + RBAC授权机制,读写权限可以控制到单个文件的粒度;
- 存储层的选型:职责分离 —— 维护期间在Git,运行期间在Kubernetes背后的etcd,由CI/CD Pipeline自动同步Git到集群。既易维护,又保持了K-V存储服务的架构简单;
- 安全性:Kubernetes天然的TLS双向认证体系,传输是安全的。另外,Kubernetes Secret天然支持云服务商的KMS集成,更严格的权限控制,所有的密钥是单独管理、单独挂载到服务运行实例上的,压根不会出现在Git中;
- 高可用、数据一致性:背后的ectd集群使用Raft算法保障一致性。虽然etcd是CAP取CP,但即使整个K8S集群不可用,也不会影响任何已经运行的服务,因为ConfigMap/Secret早已在初始化Pod的容器阶段,就挂载成了普通的文件/环境变量;
- 版本控制:运行期etcd只保留个别历史版本,完善的版本管理职责,转移给了Git这样一个天然的版本控制系统。
客户端:文件/环境变量就是最原始的配置方式,应用层没有任何额外性能开销和学习使用成本,也天然兼容任何现有的技术栈,只需要在文件变化时在应用层做一次reload即可。对,Spring Boot Dynamic Config项目干的就是这个事。
注:每个K8S集群节点上运行的Kubelet,虽然会Watch资源的实时变化,但真正的更新是在1分钟的同步周期做的,也就是说配置修改在1分钟内会在所有运行实例中生效。这个机制是对Kubernetes API Server的请求削峰和保护,对于小型集群可以在Kubelet的启动参数减小“syncFrequency”的默认时间,加速配置生效。
下面是在Kubernetes中使用的Yaml示例片段。
# 1. 前提: 在Jenkins/Argo CD/Github Actions中,
# 创建Config Git Repo到Kubernetes ConfigMap的同步Pipeline
# 2. 在声明的K8S Deployment中,
# 添加环境变量 SPRING_CONFIG_LOCATION
# 指向Config Map mountPath,注意需要'/'结尾
kind: Deployment
apiVersion: apps/v1
metadata:
spec:
template:
spec:
volumes:
- name: conf-path
configMap:
name: your-app-config
containers:
- name: app-container
image: '<your-image-name>'
env:
- name: SPRING_CONFIG_LOCATION
value: /config/
# Spring支持 Relaxing Binding,使用 -jar xxx.jar --spring.config.location 也可以
command: ["java", "-jar", "your-spring-boot-app.jar"]
volumeMounts:
- name: conf-path
mountPath: /config总结与思考
本文主要介绍了我最近开发的一个实现Spring Boot动态配置的轻量级库:Spring Boot Dynamic Config,以及为什么结合Git + Kubernetes的配置管理模式,优于其他配置管理组件。
使用场景
技术是解决问题的,脱离问题场景做选择是没有意义的。
- Nacos适合有历史包袱的项目、未容器化的项目,应用层不得不借助Nacos这类组件,实现一些通用能力。
- 对于已经上了Kubernetes的系统,结合DevOps的持续交付流水线,使用Spring Boot Dynamic Config是最简洁高效的解决方案。
- 当然,对于简单的场景,在3,5台机器上直接跑个位数的服务,即使没有容器化、没有DevOps流水线,直接SSH到服务器去改配置文件,这时用Dynamic Config也是比单独部署配置服务更简单的一条路。
少即是多
我开发这个库的动机,是在参与数十个微服务应用的DevOps工作时,看着运维同事深陷大量环境和服务的配置管理泥坑,我开始反思一个问题:配置管理有必要如此复杂吗?
当我们已经有了Git、有了Kubernetes,那么,Git不就是那个最完美的配置管理系统吗?Kubernetes不就是那个最完美的配置中心吗?踏破铁鞋无觅处,得来全不费工夫。
Keep it simple and stupid !
Kubernetes + X
Kubernetes + Git解决了复杂微服务系统的配置管理问题。其实,Kubernetes + X的组合几乎可以解决掉服务治理的所有问题。而开发人员很少了解Kubernetes这样强大的云原生平台,认为Kubernetes仅仅是部署运维的工具。我以后还会再写一些文章来说明:为什么在Kubernetes体系下,许多组件和轮子是不必要的,包括主流的Spring Cloud生态的诸多组件。之前也曾写过一个简单的回答:https://www.zhihu.com/question/430048535/answer/1582533126
项目的开发历程
为什么造这个轮子?
Kubernetes ConfigMap/Secret已经是主流的云原生配置方案,而Java Spring生态缺少一个动态感知ConfigMap/Secret变化的轻量级库。Spring Cloud Kubernetes (https://spring.io/projects/spring-cloud-kubernetes) 这个库采用直接调用Kubernetes API的方案,一方面这个库过重了;另一方面与Kubernetes耦合过于紧密,启动服务还需要访问Kubernetes API的权限,不合适。
效果如何?
这个小轮子一共花了一周多的业余时间,一小半的时间在解决疑难杂症,还有一小半的时间在写文档、改进单元测试和代码质量。
最终,精简到仅有600多行实现代码,无任何除了Spring Boot核心库以外的依赖。同时开发了400多行单元测试,测试覆盖率95%,CodeBeat代码质量评分在A/B级之间。
再贴一下项目地址,使用方法打开就可以看到:https://github.com/Code2Life/spring-boot-dynamic-config 。欢迎小伙伴们使用、Star、PR!