Why Tensor Fusion is the Game Changer in GPU Virtualization
Background
Recently, while working on our company's cloud cost optimization, most cloud resource cost control strategies were clear, but the exorbitant GPU fees remained a headache.
In October, I caught up with an old friend who happened to be researching GPU virtualization. After seeing his prototype, my intuition told me it will be a revolutionary technology, possibly it could create a unicorn-level company.
We immediately aligned our vision and started working on the project in our spare time, naming it Tensor Fusion.
As our research into GPU virtualization deepened, I compiled some valuable insights that both answer why we're committed to this venture and demonstrate to users or investors where our product value lies.
Before diving into the technical discussion, you can check out the Demo to understand what Tensor Fusion is. The docs are available here: Get Started. We welcome trials and feedback.
After reading this article, you'll have answers to these questions:
- Why is GPU virtualization necessary?
- What are the technical approaches to GPU virtualization, and what are their core principles?
- What are the pros and cons of these GPU virtualization technologies?
- Why hasn't the industry produced a perfect GPU virtualization and pooling solution yet?
- What gives us the confidence to say we can revolutionize this field?
Why GPU Virtualization is Needed
While investigating GPU cost issues, I noticed that each service instance exclusively occupied a GPU. Although individual GPU utilization could reach 70% during peak business hours, the overall GPU cluster utilization never exceeded 20%.
This example perfectly illustrates why GPU virtualization is necessary. Without virtualization, there's no way to safely share GPUs, meaning 80% of resources are wasted, paying cloud providers 400% more than necessary!
In professional terms, GPU virtualization serves these purposes:
- Virtualization is a means to share underlying physical resources, avoiding waste of expensive GPU resources
- Virtualization can isolate failures, memory addresses, and control quotas, which is prerequisite for secure multi-tenancy
- Virtualization is the foundation for elastic scaling, enabling reduced tail latency and increased throughput during high concurrency.
IaaS has been developing for years, and CPU virtualization is almost perfect, but GPU is still used in mounting physical devices way, which is obviously unreasonable.
Can GPU virtualization be achieved? Yes, there are several solutions in the industry, and what are the problems?
4 GPU Virtualization Approaches
Currently, there are 4 solutions in the industry, and we'll discuss them from low to high in terms of abstraction:
- Hardware and driver layer built-in sharing mechanisms, strictly speaking, not virtualization
- Virtual devices implemented para-virtualization
- Fake virtualization based-on co-located task scheduling
- GPU Computing Power virtualization based on API forwarding
Hardware and driver layer sharing mechanisms
GPU hardware and driver layer has built-in multi-user isolation and sharing mechanisms, and each GPU manufacturer has its own implementation.
For example, NVIDIA's built-in sharing mechanisms mainly include 3 types:
- Multi-instance GPU (MIG) ,Multi-instance GPU. Similar to cutting cake, dividing the GPU into several completely isolated parts, but only 7 sub-GPUs can be produced at most, and the memory isolation is GB-level,only supported by Ampere architecture after 2020.
- Time-slicing is the popular oversubscription way in Kubernetes. It lacks memory and fault isolation. NVIDIA just presents a single GPU as multiple devices to different Pods. There's no control over Pods launching multiple processes to compete for time slices. Think of it like a buffet line with no portion control - nothing stops one person from taking everything.
- Multi-process Service (MPS) is a variant of Time-slicing that shares CUDA Context across multiple processes. This allows the MPS scheduler to insert tasks whenever CUDA cores are idle, rather than relying on concurrent execution and CUDA context switching like Time-slicing does. Prior to 2017, NVIDIA provided MPS scheduling through a software-layer mps-server. With the introduction of Volta architecture GPUs, MPS expanded to support up to 48 simultaneous processes and added memory address space isolation, though it still lacks OOM protection and fault isolation. In most cases, MPS achieves higher efficiency than Time-slicing. Think of MPS like a restaurant wait list system - as soon as a table opens up, the next customer can be seated.
To sum up, MIG is space division multiplexing (Space division multiplexing), Time-slicing and MPS are time division multiplexing (Time division multiplexing), the detailed comparison can refer to this document.

Combing MIG and Time-slicing/MPS can achieve a similar effect to GPU virtualization, but the granularity is too coarse to fundamentally improve GPU utilization, and none of them can achieve VRAM oversubscription, if Time-slicing is used, it will also bring reduced availability and increased latency risks.
In real cases, although this solution cannot achieve fine-grained resource control over GPUs, it is simple and easy to implement, and can meet the most basic business needs when combined with Kubernetes cluster's pooled scheduling capabilities.
There is an open-source project Nebuly NOS based on NVIDIA's MIG+MPS to dynamically split GPU devices in Kubernetes, which is more automated and has better scheduling effects than NVIDIA's native Kubernetes solution.
Para-virtualization with Virtual Devices
1. What are Virtual Devices?
Virtual I/O devices have evolved for years in IaaS - this is the "orthodox approach" to GPU virtualization.
When implementing virtual devices, pure software emulation (full virtualization) is typically avoided to minimize performance impact. Instead, para-virtualization is used to balance performance and security.
The basic idea is: isolating the dangerous device control layer in the hypervisor while passing through the device data and functional layers directly to VMs.
Virtual devices are technically complex, involving things like IOMMU for memory page table isolation and driver function pointer isolation, which we won't detail here.

2. Three Variants of Virtual Device Implementation
There are 3 variants for implementing GPU virtual devices: VFIO + SR-IOV, GRID vGPU, and VirtIO.
- VFIO + SR-IOV: Think of VFIO as "VF" (Virtual Function) + "IO". VMs call VFs which map to PFs (Physical Functions) on the device. SR-IOV is a PCIe device virtualization standard - when hardware vendors support it, hypervisors can manage device's logical replications accordingly. AMD mainly uses VFIO+SR-IOV for GPU virtualization, with performance loss under 4%.
- GRID vGPU: This is NVIDIA's proprietary commercial virtual device solution. NVIDIA developed GRID vGPU early on, keeping it closed-source with expensive licensing, and some cloud vendors develop their own NVIDIA GPU virtualization. It uses Mediated Device (mdev) and modified drivers to achieve similar effects to VFIO + SR-IOV. As the world's highest-valued company, NVIDIA sets its own standards. Before that, Intel's GVT used a similar approach.
- VirtIO: Predating SR-IOV, VirtIO injects a "fake driver" into VMs. The hypervisor reads I/O requests from host-guest shared memory and forwards them to the "real driver" on the host. It introduces "frontend" and "backend" driver concepts, with only the flexible frontend visible in VMs. Performance loss is slightly higher but offers more flexibility. The qCUDA project demonstrates this approach.
In practice, cloud vendors selling GPU VMs need traditional virtual device solutions, leading to proprietary implementations like Ali Cloud cGPU.
3. Why Virtual Devices Aren't the Ultimate Solution
While virtual devices look promising with MB-level memory control and 1%/10% compute control per GPU, running in OS kernel space with proven security technologies, they aren't the complete answer.
Is virtual device the perfect state of GPU virtualization?
Of course not.
Just ask one question: What does users want?
Does users need a VM with a GPU? Is it the 6912 CUDA cores and 4200MB VRAM on the GPU?
No, they don't.
Think from the first principles, users needs: to train/infer various neural network models to achieve business goals. So, there needs to be something that helps them perform tensor calculations at a rate of trillions of floating-point operations per second.
Is there a way to handle multiple tenants' requests as quickly, efficiently, and securely as possible in a limited GPU resource pool?
Thinking to this dimension, the virtualization of GPU devices is no longer important, offering TFLOPS, isolating and sharing computing power -- that is the true virtualization that meets user needs.
From the business perspective, what are the limitations of the virtual device approach?
- The resource quota of virtual devices is fixed and cannot be adjusted dynamically according to business peaks and troughs, thus the overall resource utilization is still not as high as expected
- CUDA cores can be oversubscribed, but generally cannot oversubscribe VRAM, but VRAM is likely to be the bottleneck, deploy much more AI apps for the business is not possible
- Physical GPU devices must be mounted on the host, and drivers must be mounted on the business running environment, affecting elasticity and increasing management complexity
- It is very hard to jointly accelerate a set of computing tasks across multiple GPUs on different machines, so business latency cannot be reduced
- Too dependent on hardware vendors, it is impossible to build a heterogeneous cluster with multiple GPU vendors, business is still easily locked by GPU vendors
Co-located task scheduling emulation
Among those limitations of virtual devices, the first one is the most serious: When business has obvious peaks and troughs, GPU utilization still not improved.
Therefore, there is a third type of solution emerged. The key innovation is: Drilling down scheduling from a coarse device level to a fine computing task level.
This approach adds a "broker" layer above the GPU devices. Users just tell the broker what target GPU utilization they need.
It's similar to hiring a contractor instead of individual workers. The contractor can efficiently manage multiple projects by assigning tasks to workers as needed, which works better than clients trying to manage workers directly.
How is this implemented? The system allows multiple applications to concurrently execute compute tasks on one GPU, called "co-location tasks". Applications call user-space compute libraries like NVIDIA's libcuda and AMD's HIP SDK. By intercepting at this layer and adding a rate limiter, they can precisely control how these co-located tasks flow into physical devices and manage resource quotas.
This interception is typically done using LD_LIBRARY_PATH / LD_PRELOAD in user space, resulting in minimal performance overhead. The rate limiter usually uses a token bucket algorithm and polls GPU metrics via the nvml library.
Above the scheduler, compute quota interfaces are exposed to users through Kubernetes Device Plugins. Users can specify requests/limits like "nvidia.com/vgpu: 1%" in their resource specifications. Combined with native or custom Kubernetes schedulers, this enables cluster-level pooled compute allocation.
While the result resembles virtual devices, it lacks memory address isolation and fault isolation, so it's not strictly virtualization. We'll call it "co-location task scheduling emulation".
Here are some notable implementations from academia and industry:
- Gaia GPU: Implementation from a paper in 2018 by Tencent and Peking University paper with 43 citations. Most similar research since then has built upon GaiaGPU's foundation
- KubeShare & Kernel Burst: Introduced kernel burst concepts and task execution prediction to improve scheduling efficiency, enabling Auto Scale on single GPUs
- Ark GPU: Added load prediction models and QoS differentiation between LC (Latency-Critical) and BE (Best-Effort) workloads
- Project HAMI: A CNCF Sandbox project (formerly k8s-vGPU-scheduler) focused on production deployment across multiple cloud providers. Core interception code in HAMi-core is nearly identical to GaiaGPU
- RUN AI: An Israeli startup that has raised $118M, likely building on GaiaGPU while adding enterprise features like dynamic scheduling and GPU cluster management console

An interesting project is HuggingFace ZeroGPU, where CEO Clem Delangue invested $10M to build a free A100 inference cluster for AI developers. The key code in Gradio SDK hooks PyTorch APIs rather than NVIDIA Driver APIs. It uses the @space.GPU decorator to intercept Python inference functions, letting the scheduler manage GPU quotas. When resources are available, it executes on local 8xA100s and swaps memory to NVMe when functions cool down.

While ZeroGPU's high-level API hooking enables GPU time-sharing and QoS, it can't finely control VRAM per application - each app can use up to 40G VRAM of A100.
In summary, this third approach of co-located task scheduling virtualizes at the compute power level. By adding rate limiters to AI compute libraries and leveraging Kubernetes' native pool scheduling, it achieves relatively flexible resource control and multi-tenant sharing.
But this is not enough. Why?
Besides not solving problems #2/3/4/5 of the virtual device approach mentioned above, looking at the entire GPU pool, there are several unsolved challenges about multi-tenancy and pooling:
- Still bound to GPU devices - CPU and GPU scheduling remain coupled, making independent scaling impossible. Can't achieve GPU Scale to Zero with sub-second warm-up.
- From a cluster perspective, while Kubernetes enables some pooling through distributed scheduling, there's no active defragmentation or GPU pool auto-scaling. Scheduling efficiency can't reach the next level and operational costs remain high (only run.ai among mentioned solutions does active scheduling and defragmentation)
- No fault isolation or memory address isolation, making it unsafe for untrusted multi-tenant sharing.
Can we think one step further along this path to thoroughly solve these issues?
API Remoting Compute Virtualization
Let's return to first principles and think deeper to find the fundamental solution.
To achieve ultimate GPU compute sharing, we need to consolidate all compute power into one large pool for fine-grained scheduling across the entire pool.
It's like solving storage efficiency at the IaaS layer, where distributed NFS/Object Storage has become the de facto standard. NFS turns disks into remote storage services, enabling compute-storage separation.
Similarly, by turning GPUs into remote compute services and implementing GPU-CPU separation, we can create an architecture with compute fusion + fine-grained scheduling control - using GPUs like NFS!
The ultimate state after GPU pooling is that every application can utilize all GPU resources. It's why we named our product Tensor Fusion.
Here's an interesting analogy - have you wondered why birds have such small brains yet match mammals in intelligence?
The human brain structure below has dedicated regions for each sense - like assigning separate GPUs/vGPUs to each AI model.

In contrast, bird brains aren't divided into regions. The cross-section below shows how each sense can utilize the entire brain for neural computation - this is the Tensor Fusion effect.
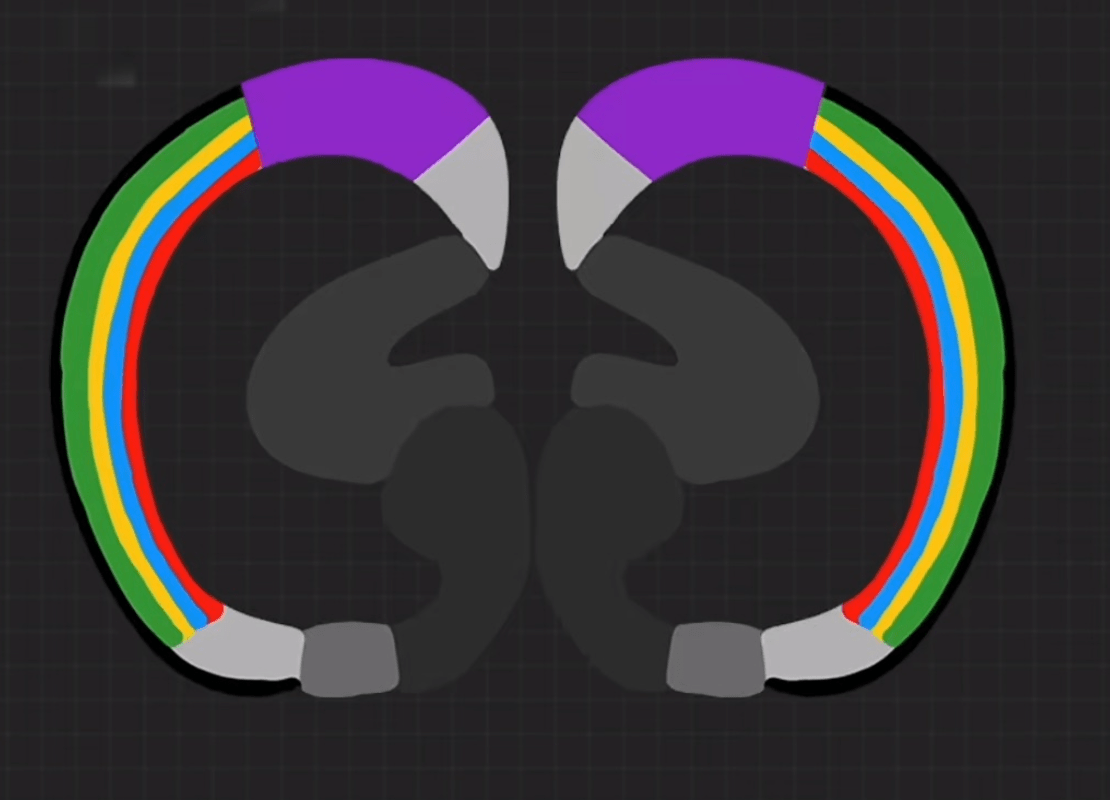
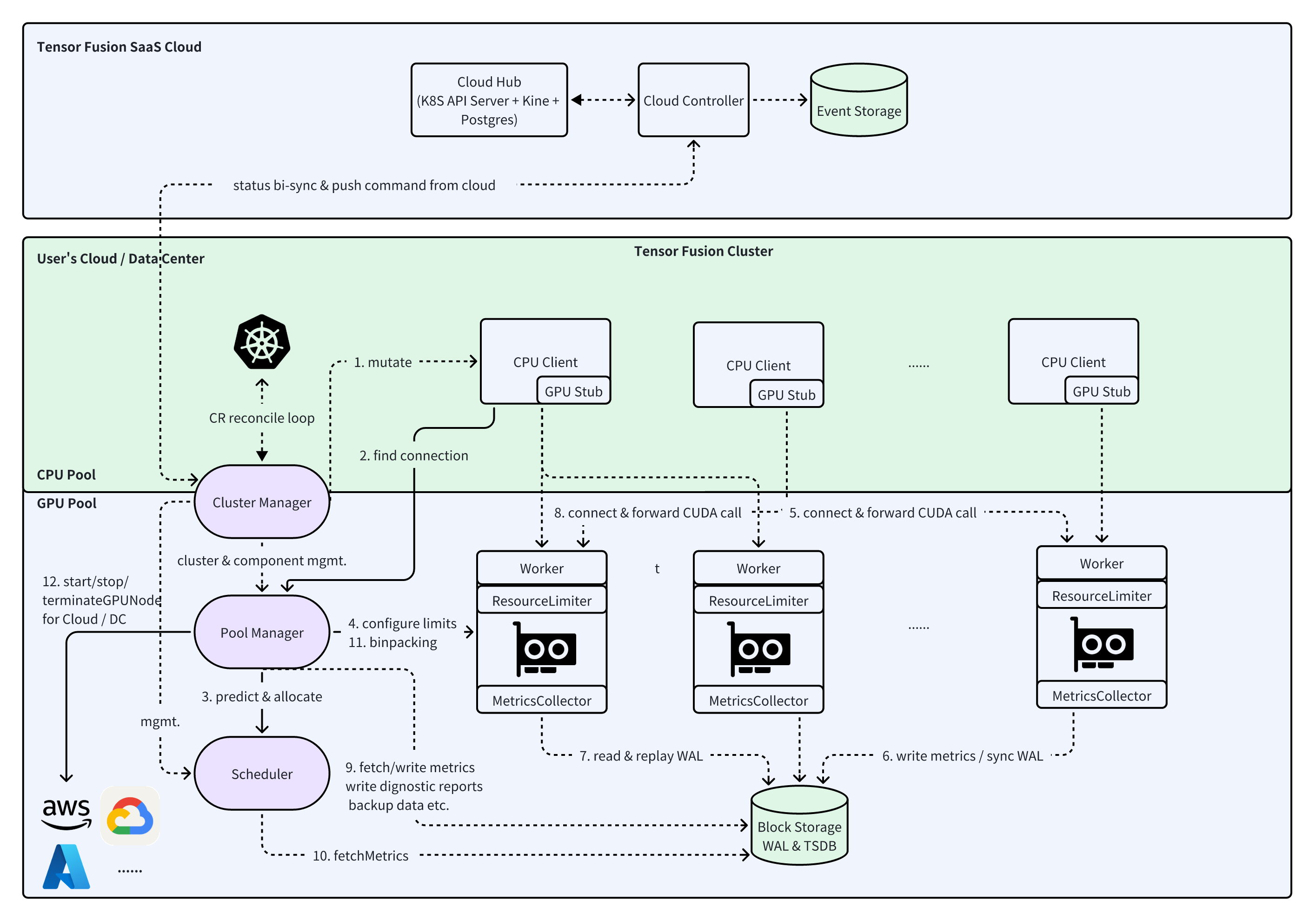
While biological evolution can't "undo" mammalian brain structure, we can learn from bird brains in software design. With GPU-CPU separation architecture and fused GPU compute pools, we can solve all previous issues from a higher dimension:
- GPU utilization: Our GPU-as-service creates a magical control plane that can achieve scheduling, binpacking, and elasticity of both GPU nodes and AI workloads. This game-changing pool shaping capability transforms utilization from mediocre to magnificent!
- Oversubscription bottlenecks: GPU-CPU decoupling removes host CPU/Memory constraints on GPU oversubscription. The critical VRAM shortage is easily solved by supplementing with memory/NVMe as "fake VRAM" for low-QoS workloads, swapping to real VRAM in milliseconds when needed, breaking through the VRAM oversubscription barrier.
- Business-GPU coupling: With remote GPU pooling, AI infra and AI apps separate concerns. AI apps can run on machines without GPUs and drivers - just auto-injected KB-sized libcuda stub to run any CUDA program non-intrusively. The hefty 3-6GB PyTorch/CUDA/CUDA-cudnn images slim down to MB-scale. Decoupling also enables cross-machine multi-GPU acceleration to reduce latency and increase throughput.
- GPU vendor lock-in: Tensor Fusion could be used with ZLUDA, which lets you mix different GPU brands in one cluster. All GPUs provide the same CUDA APIs. No need to rewrite code when changing GPU vendors.
- Virtualization security: Remote compute virtualization with local stubs makes it safer. Better fault isolation and memory protection for multi-tenant GPU sharing.
While API remoting compute virtualization and pooling seems perfect, how feasible is it?
Academia explored this path early on, pioneered by the rCUDA paper with 400+ citations. The basic principle is intercepting CUDA APIs via LD_LIBRARY_PATH or LD_PRELOAD for network forwarding, creating shadow threads/processes on GPU-equipped servers to replay client CUDA calls.
However, destiny's gifts come with hidden costs.
While compute virtualization has an elegant architecture, intercepting and implementing all compute library APIs are required, heavily optimizing to avoid network forwarding overhead makes it far more technically challenging and labor-intensive than the previous three approaches.
rCUDA stopped updating 4 years ago; GPULess only implemented 60+ CUDA function stubs; commercial product BitFusion was acquired by VMWare and discontinued last year.
Our predecessors proved the feasibility, and now a new generation of geeks continues exploring this path. For competitive analysis, I've compiled all similar existing products:
- VirtAI Technology: Not open source, likely using Remote CUDA API forwarding or a combination of technologies based on product descriptions. VirtAI raised $30M in 2020/2021. They focus on the Chinese market, adapting CUDA for domestic GPU vendors, with no apparent international expansion plans - different from Tensor Fusion's target market.
- Project scuda: A new open source project from 2 months ago. While its codebase is far less mature than Tensor Fusion, it gained 550+ stars in just 2 months, showing strong industry demand for a practical rCUDA solution.
- ThunderCompute: Received $500K Pre-Seed funding from YC/AWS/GCP/NVIDIA 5 months ago. They focus on selling compute power, letting clients use remote GPU pools over the internet. We tested internet-based solutions but found latency too high for AI inference. From a business perspective, building GPU pools to sell compute isn't optimal - while they have strong tech, their business strategy needs adjustment.
- JuiceLabs: Raised funding 4 years ago, but no widely-used products or recent funding rounds visible.
In summary, only VirtAI and ThunderCompute have achieved commercial impact in CUDA API network forwarding and GPU pool scheduling. The existing companies prove both the technical feasibility and business value of this approach.
This is a challenging but correct path that few have taken.
Where are Tensor Fusion's opportunities?
With some startups working on similar solutions, where do we see opportunities for Tensor Fusion?
Our research shows we don't overlap with other companies using the fourth technical approach. When competing with products using the first three approaches, beyond our architectural advantages, we have strong confidence in our market positioning, product offering, team capabilities, and technical expertise.
Market
- The GPU hardware market has reached $61.58 billion in 2024. With a 28.6% CAGR, it will grow to $461.02 billion by 2032. This growth propelled NVIDIA to become the world's most valuable company, holding more than 95% market share in 2024. Assume GPU efficiency management market is mere 1% slice of the GPU hardware market, it represents a $610M opportunity in 2024. Moreover, few AI infrastructure companies compete in this emerging blue ocean market.
- For target market, Tensor Fusion focuses on serving global cloud providers and AI SaaS companies with GPU clusters. Our main competitor is Run.AI, which is using the third type of virtualization and scheduling approach, we're very confident that surpassing Run.AI is just a matter of time.
- Our market strategy starts with small/medium cloud providers and AI SaaS companies for solution validation, gradually expanding to larger players like HuggingFace and AWS.
Product
In terms of product maturity, Tensor Fusion is currently the only solution offering remote GPU pooling + virtual VRAM expansion + dynamic scheduling in global market, and has already been validated in production by a customer in Asia.
This customer runs an AI hands-on lab platform where users get access to ComfyUI/SD environments for AI image generation, with customizable workflows and model selection.
After deploying Tensor Fusion, ComfyUI/SD runs on inexpensive CPU-only VMs. GPU resources are only allocated on-demand when users execute image generation tasks. After 10 seconds of inactivity, VRAM is swapped out and the GPU is shared with other users.
The system deployment reduced the costs of the AI lab platform by 90% while solving GPU inventory shortage issues with their cloud provider.
As a product, Tensor Fusion provides an end-to-end GPU efficiency management solution, optimizing scheduling efficiency, observability, and stability with a focus on serving cloud providers and AI SaaS companies.
Our product strategy avoids competing with customers by building our own compute pools. Instead, we partner with cloud providers and AI SaaS companies to provide AI infrastructure products and technical consulting, building long-term product and channel moats.
Team
The Tensor Fusion prototype was developed by my friend and former colleague Andy, a serial entrepreneur and the creator of a mvisor, Andy brings exceptional creativity and low-level programming expertise.
As co-founder, I bring technical expertise in IaaS/PaaS and connections with international cloud providers. With experience in product, technology, marketing and management from internal startups, I'm confident in leading business operations and product development.
Post-funding, we plan to formally bring on 2-3 additional talented engineers with strong entrepreneurial drive.
We are actively seeking a Sales and Operations leader to join as a potential co-founder, with a focus on international markets.
Technology
Beyond our architectural advantages, we have three key technical differentiators:
- Proprietary optimizations: Our team's deep CUDA and virtualization expertise has enabled us to develop patentable innovations in memory-to-VRAM expansion, kernel acceleration, and high-performance protocols. These create significant technical moats that would take competitors years to replicate, protecting our first-mover advantage.
- Advanced scheduling: We're developing GPU context hot migration + AI-based dynamic scheduling. This JIT proactive scheduling approach creates a generational advantage over traditional AOT passive allocation via Kubernetes Schedule Plugins.
- Seamless integration: Using Kubernetes ecosystem and cross-domain technologies, we've achieved zero-touch onboarding and zero-config migration, dramatically reducing adoption costs - a capability unmatched by any existing solution.
Conclusion
This article introduced the background and purpose of GPU virtualization, explaining 4 technical approaches from academia and industry.
Through progressive analysis, we answered why Tensor Fusion chose API remoting way, and explored our opportunities in the AI infrastructure GPU cluster efficiency management space, along with why we're uniquely positioned to succeed.
My deep belief in Tensor Fusion's value comes from a core truth about cloud computing: Cloud platforms - whether IaaS, PaaS, or SaaS - create value through efficient resource sharing.
In IaaS, this mechanism of abstraction, isolation, and scheduling to enable sharing, is called virtualization.
The essence of virtualization and resource sharing in IaaS lies in transforming physical resources with high marginal costs into logical resources with minimal costs. This transformation happens through robust isolation and precise scheduling, leading to improved efficiency.
Therefore, we believe Tensor Fusion has the opportunity to become a rising star in AI infra, helping the AI wave transform the world.
We are currently seeking investment partners who understand core technical innovation and have global market resources. We welcome inquiries from interested investors.

Reference
- Duato, José, et al. "rCUDA: Reducing the number of GPU-based accelerators in high performance clusters." 2010 International Conference on High Performance Computing & Simulation. IEEE, 2010.
- Reaño, Carlos, and Federico Silla. "Redesigning the rCUDA communication layer for a better adaptation to the underlying hardware." Concurrency and Computation: Practice and Experience 33.14 (2021): e5481.
- Tobler, Lukas. Gpuless–serverless gpu functions. Diss. Master’s thesis. ETH, 2022.
- Gu, Jing, et al. "GaiaGPU: Sharing GPUs in container clouds." 2018 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Ubiquitous Computing & Communications, Big Data & Cloud Computing, Social Computing & Networking, Sustainable Computing & Communications (ISPA/IUCC/BDCloud/SocialCom/SustainCom). IEEE, 2018.
- Song, Shengbo, et al. "Gaia scheduler: A kubernetes-based scheduler framework." 2018 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Ubiquitous Computing & Communications, Big Data & Cloud Computing, Social Computing & Networking, Sustainable Computing & Communications (ISPA/IUCC/BDCloud/SocialCom/SustainCom). IEEE, 2018.
- Liu, Zijie, et al. "KubFBS: A fine‐grained and balance‐aware scheduling system for deep learning tasks based on kubernetes." Concurrency and Computation: Practice and Experience 34.11 (2022): e6836.
- Yeh, Ting-An, Hung-Hsin Chen, and Jerry Chou. "KubeShare: A framework to manage GPUs as first-class and shared resources in container cloud." Proceedings of the 29th international symposium on high-performance parallel and distributed computing. 2020.
- Chen, Hung-Hsin, et al. "Gemini: Enabling multi-tenant gpu sharing based on kernel burst estimation." IEEE Transactions on Cloud Computing 11.1 (2021): 854-867.
- Lou, Jie, et al. "ArkGPU: enabling applications’ high-goodput co-location execution on multitasking GPUs." CCF Transactions on High Performance Computing 5.3 (2023): 304-321.
- Hong, Cheol-Ho, Ivor Spence, and Dimitrios S. Nikolopoulos. "GPU virtualization and scheduling methods: A comprehensive survey." ACM Computing Surveys (CSUR) 50.3 (2017): 1-37.
- A Closer Look at VirtIO and GPU Virtualisation | Blog | Linaro. www.linaro.org/blog/a-closer-look-at-virtio-and-gpu-virtualisation
- Brief Introduction of GPU Virtualization | Blog | Aliyun. developer.aliyun.com/article/590916
- Run TorchServe with Nvidia MPS | Blog | Github. github.com/pytorch/serve/blob/master/docs/nvidia_mps.md